-
ag百家乐两个平台对打可以吗 Claude新指南,教你构建属于我方的智能体
发布日期:2024-12-26 03:25 点击次数:75本文来自微信公众号:王智远ag百家乐两个平台对打可以吗,作家:王智远,原文标题:《Claude发布一套智能体构建指南》,题图来自:AI生成
上周五,2024年12月20日。Anthropic这家AI公司发布一份答复,题目是《Building effective agents》(构建高效的智能代理)。
你可能没听过Anthropic,但他们的家具你可能知谈,比如Claude系列的AI助手,有Claude 3.5 Haiku和Claude 3.5 Sonnet等等。
这份答复,是基于他们往常一年与数十个团队互助构建LLM(大说话模子)代理系统的教悔追溯。我周末看了,不详有五点内容:
1. 对代理系统Agents的界说;
2. 相干什么时候用代理系统;
3. 五种中枢的责任流模式;
4. 一些现实中的例子;
终末,给成就者提供一些践诺融会。
我以为内容对成就者,或者对智能体、责任流感兴趣的东谈主挺有匡助;是以,把有价值的内容交融后,跟你申报下。
一
Agents不少东谈主听过,Anthropic这家公司若何交融的呢?他们认为,代理不错有好多种界说。
有些客户把代理看作统统零丁的系统,不错万古分自主运行,使用多样器用来完成复杂的任务;另一些客户则把这个词用来描述那些按照事前设定的历程运行的系统。
在Anthropic,把统共这些不同的体式王人叫作念代理系统(agentic systems),但在责任流(Workflows)和代理(Agents)之间,有很大的区别。
区别在哪呢?
责任流,是提前写好的代码来协调东谈主和器用的系统;代理是我方动态治理我方的历程和器用使用,保捏对完成任务样式的限制。
这种区别很首要,因为它帮咱们交融了代理系统的实验:即,不是统共的AI援救系统王人得统统自主,只怕候一个提前设定好的责任流更得当某些情况。
那么,什么时候该用责任流、什么时候该用智能体?
其认为,如果任务界说得很明晰,责任流更得当,因为它能提供可展望性和一致性。
如果要大鸿沟的天真性和模子驱动的决策,代理是更好的选拔,但对好多哄骗来说,优化单个LLM调用,配合检索和高下文示例频频就够用了。
鄙俚地说:责任流更得当任务明确、模式固定的责任。就像你按照食谱作念菜,每一步王人写得清清醒爽,惟有随着作念就行了。
而智能体得当要天真应酬、顺风张帆的情况。比如:你要去一个新城市冒险,莫得固定的阶梯,要左阐发验情况来决定下一步若何走,此时,智能体能帮你在复杂多变的环境中作念出决策。
对于界说,这是第一部天职容。第二部分是什么呢?
Anthropic建议,咫尺,看到市面有四种流行成就框挺火。分歧是:LangChain的LangGraph、Amazon Bedrock的AI Agent框架、Rivet和Vellum。
敬佩你看到名字有些交融不透,别浮躁,我和你相似,于是,索性查了一下。
先说说LangChain。它是一个器用,帮咱们创建和治理说话模子(LLM)的责任流。你不错把它遐想成一个图表,帮成就者把不同的任务和模式连起来,这么,就能明晰地知谈每一步该若何作念,改动起来也浅近。
接下来是Amazon Bedrock的AI Agent框架。
这是亚马逊提供的一个框架,像一个器用箱,内部有好多现成的器用和资源;帮成就者快速搭建智能哄骗,你不错用它来蓄意和运行多样AI任务,毋庸从新驱动。
然后是Rivet,它是一个拖放式的图形用户界面(GUI)器用,专门用来构建说话模子的责任流。
咱们不错把它遐想成拼积木相似,把不同的功能和模式拖到一谈,酿成一个圆善的责任历程,这种样式粗拙直不雅,得当不太会编程的东谈主。
终末是Vellum,它亦然一个图形用户界面器用,主如果用来构建和测试复杂的责任流;蓄意完成后,你不错在Vellum里测试,确保一切通俗运行。就像一个实验室,让你不错在内部尝试多样决策。
总的来说,四个器用区别在于:LangGraph用图表和洽任务和模式;Amazon Bedrock的AI Agent框架提供全面的器用箱,让成就者毋庸从零驱动;Rivet是一个拖放式的GUI器用,得当不懂编程的东谈主;Vellum专注于复杂责任流的蓄意和测试。
Anthropic给了一个建议:
成就者不错先径直用LLM API来成就,因为好多功能用几行代码就能治理;如果要用框架,一定要弄懂底层代码,要预防,框架可能会让调试变难,别因为框架功能多就乱加复杂性。
它们还杰出提醒,客户常犯的一个极端是,对框架底层完结存诬蔑。这告诉咱们,器用仅仅帮衬,确凿首要的是交融背后的真谛。
是以,论断是:1. 框架照实能让一些基本任务变粗拙,比如调用LLM、界说妥协析器用、连络调用,但框架不应该成为咱们增多不必要复杂性的原理;2. 保捏系统粗拙、好爱慕、好调试,这才是最首要的。
二
第三部分,答复中注目先容五种中枢责任流模式。
这部分很首要,领先提到,提醒链式责任流(Prompt chaining)。若何交融?
遐想一下,你要完成一个复杂的写稿任务,比如写一篇很棒的营销案牍。你可能先写个大纲,检查一下大纲合分歧格,然后,再左证大纲写出圆善的案牍。
这种责任流的重点是,把一个大任务拆成一连串的小模式。每个模式王人是一个LLM调用来处理的,而况后头的模式会用前一个模式的恶果四肢输入。
在这个过程里,你还不错加一些检查点(答复里叫“gate”),确保一切王人在正确的轨谈上。
这种责任流最得当能明确分红几个固定小任务的情况。主要方针是让每个LLM调用王人专注于更粗拙的任务,进步举座的准确性,天然可能会多花点时分。
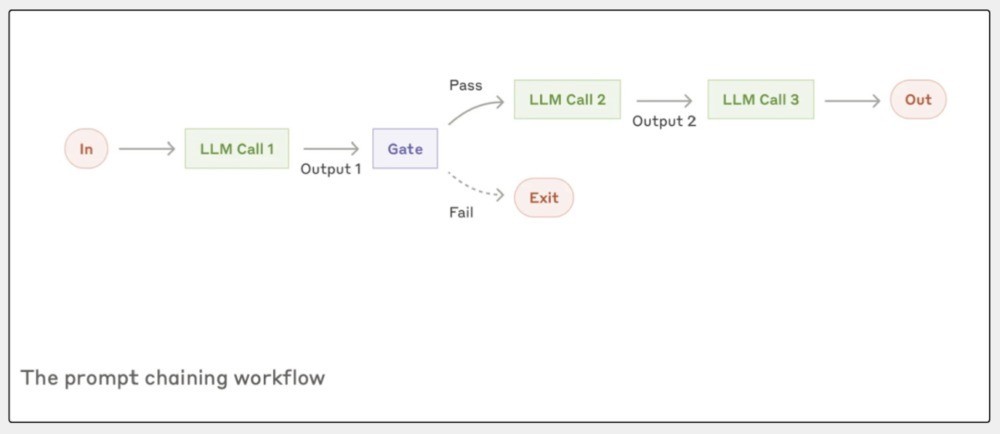
具体例子是:
文档写稿历程:第一步,生成文档大纲;第二步,检查大纲是否恰当特定规范;第三步,基于审核过的大纲写圆善文档。
上风是每个模式王人专注作念一个任务,进步准确性;不错在重要点加质料检查;历程澄莹,容易调试和优化。
第二种是:路由责任流(Routing)。
这个模式挺挑升义,处理好多用户苦求时,会际遇多样种种的问题;有的问题粗拙,有的要专科时代撑捏,还有的可能触及退款这种明锐操作。
路由责任流,重要是先对问题进行分类,然后率领到最合适的处理历程,这么作念的平允很泄露:不错针对不同类型的任务优化不同的处理样式,而不是用一个通用的目的来应酬统共情况。
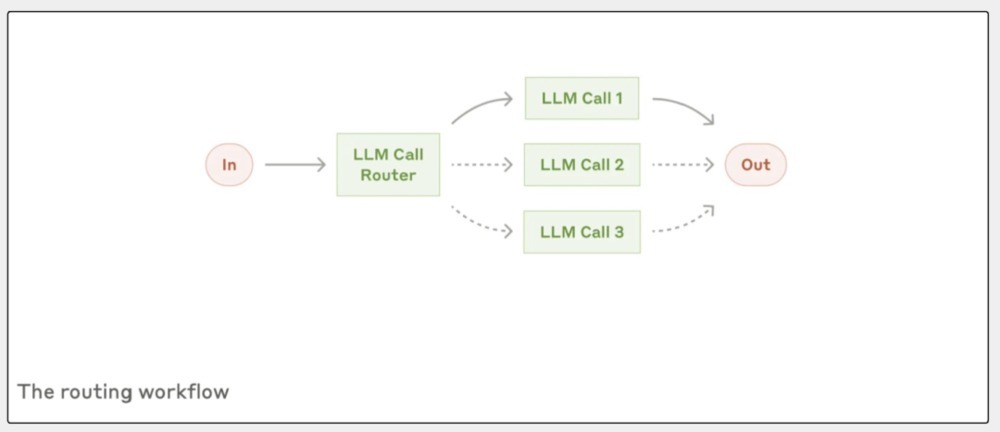
举个例子:
客户处事系统里,收到用户的问题后,2022年AG百家乐假不假路由责任流不错先判断这是个一般问题、退款苦求已经时代撑捏需求,然后分歧率领到不同的处理历程。
更贤达的是,它还能左证问题的复杂度选拔用不同才智的模子。比如,粗拙常见的问题不错交给像Claude 3.5 Haiku这么快速的模子处理,复杂或不常见的问题不错交给像Claude 3.5 Sonnet这么深广的模子来解决。
这么既能保证处事质料,又能优化资本和速率,重要是,这种分类不错通过LLM来完成,也不错用传统的分类模子或算法。
是以,它的上风在于天真性和可推广性,随着业务的发展,你不错轻视添加新的分类和处理历程,不会影响现存的功能。
三
第三种,是并行化责任流(Parallelization),这个模式得当要同期处理好多任务。
比如:你在作念一个大款式,得同期探讨好几个方面;雷同于成就软件,要一个模子来检查用户输入的安全性,同期另一个模子来生成代码。
并行化责任流,等于为了应酬这种要同期作念多件事的情况蓄意。
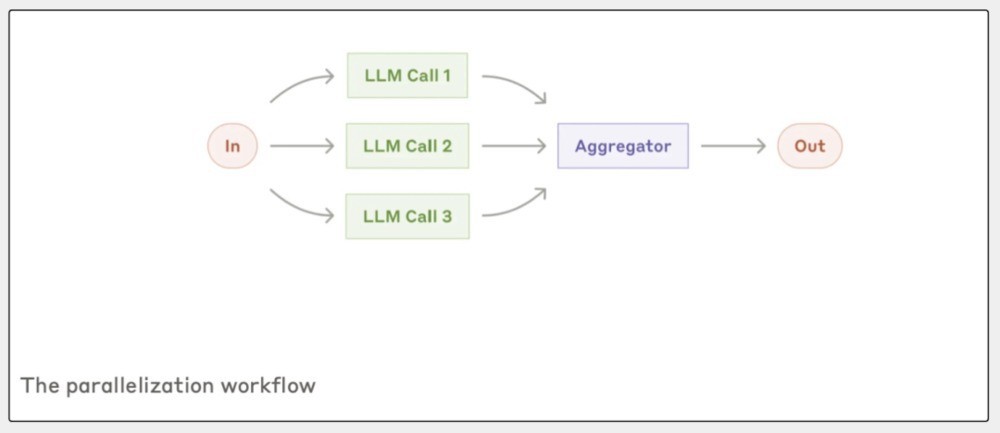
答复里说,并行化主要有两种完结样式:
1. 把任务拆成零丁的小任务,让它们同期进行,这么不错省时分;2. 通过投票机制,让好几个模子处理团结个任务,然后汇总恶果;这么作念的平允是,你能从不同的角度获取不同的输出,进步恶果的简直度。
总的来说,它像一个多功能团队,每个东谈主王人作念我方最擅长的事,一谈互助,终末获取一个更强的恶果。
第四种,协调者-责任者责任流(Orchestrator-workers)是什么?
你在组织一场音乐会,总得有个东谈主来管大局,确保每个细节王人能顺利进行,这个东谈主就像“协调者”。
其他东谈主就厚爱具体的活儿,比如:调音响、弄灯光、卖票这些,他们等于“责任者”,协调者得左证现场情况天真改动谁干什么。
答复里说,协调者-责任者责任流的点子是一个中央LLM(等于协调者)来动态分派任务,让好多责任者LLM去完成这些任务。
这么,协调者能左阐发验情况,天真决定要作念哪些小活儿,而不是一驱动就把模式王人定死了。
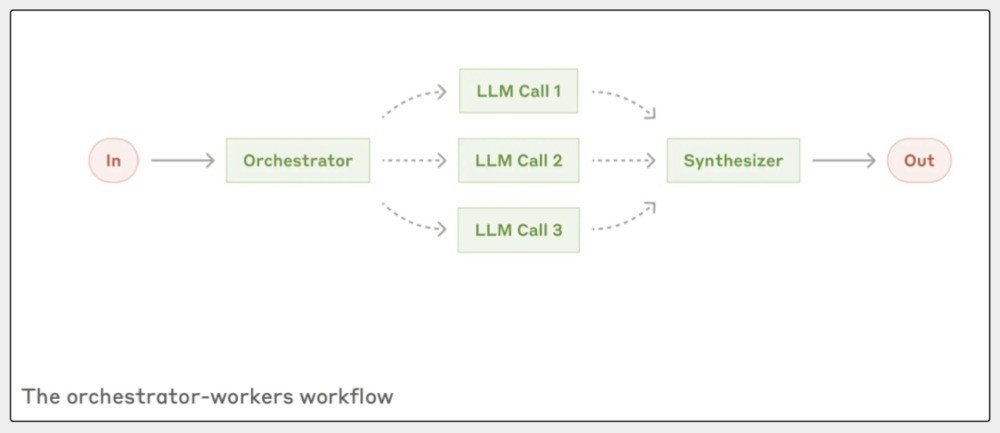
这个模式得当你没法提前知谈具体要干啥的情况,比如软件成就里的编程任务,每次左证需求,可能要改好多文献,协调者就能左阐发验情况决定哪些活儿先干,哪些不错放一放。
总之,协调者-责任者责任流就像是一位率领家。
接下来说说第五种:评估者-优化者责任流(Evaluator-optimizer),这个模式得当要反复矫正和反映的任务。
比如:你写著述,可能先写个草稿,然后请一又友望望,提提成见;你左证成见再修改,让著述更好。这个过程就跟评估者-优化者责任流差未几。
再举个例子,咱们搜一个东西可能要好几轮;评估者责任流,会望望咫尺的搜索恶果满不餍足要求,不餍足无间搜,直到找到想要的信息。
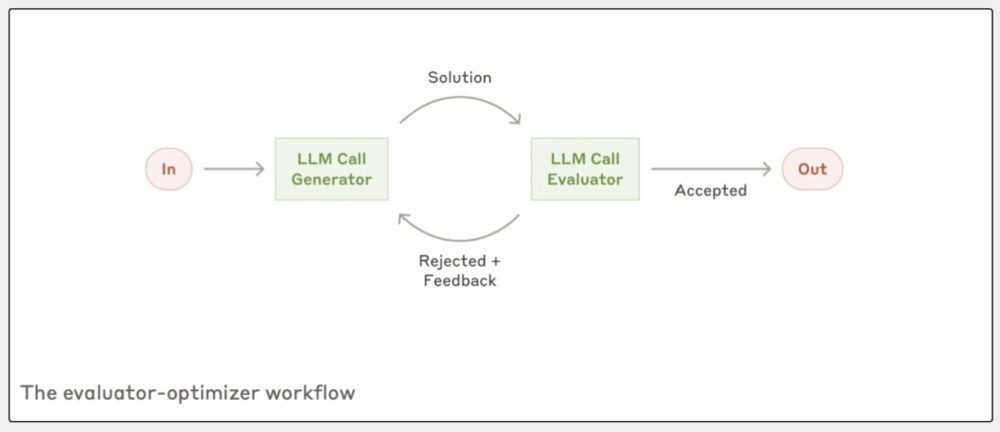
答复里说,这种责任流的重要是轮回:
一个LLM先给出初步的复兴,另一个LLM来评估这个复兴,然后提供反映,这个过程不错一遍遍重叠,直到获取一个更好的恶果。
平允在于它不错一遍遍矫正,通过不断的反映和改动,终末的输出质料能进步好多;是以,评估者-优化者责任流就像一个严格的裁剪,帮你把著述改得更好。
以上五种中枢责任流模式,你对哪一种印象相比深?
记不住也不首要,有一个目的是,用个东谈主责任的样式,去镶嵌几种模式中,望望哪些业务、款式、任务得当哪一种。
四
第四部分主要证明了:智能代理若何责任。其提到:代招待先左证用户的大叫或者和用户的互动,来搞明晰要干啥。一朝任务明确,代理就我方驱动干活。
干活时,代理得知谈周围的情况,比如用器用获取的恶果或者代码运行的反映,这么它才能知谈我方干得若何样。
如果代理在干活的时候碰到穷苦,它不错停驻来,找东谈主问问,确保任务能顺利完成;任务干结束就扫尾了,但也不错先设定好一些住手的条款,比如最多干几许次,这么能限制通盘过程。
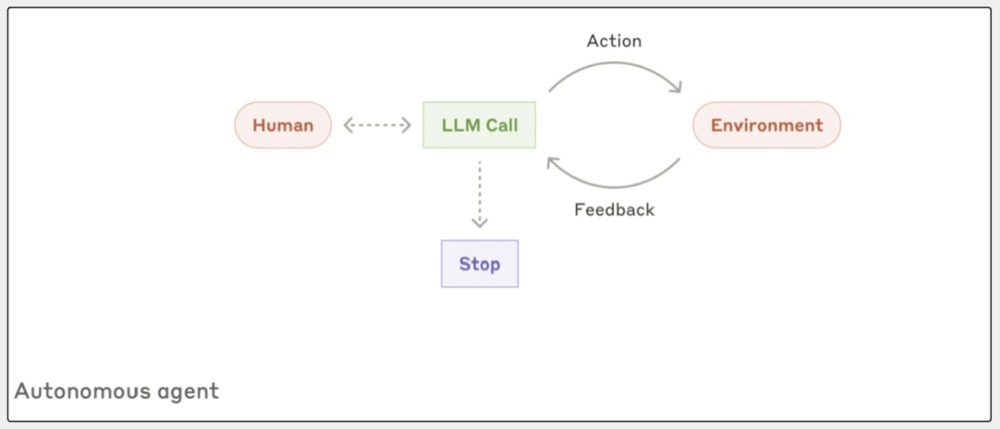
在第10页中,Anthropic给了一些实验例子。
他们强调,代理杰出得当处理灵通性的问题,尤其是模式不好展望的任务。因为代理能我方干活,是以,在信任它们的所在,它们能帮大忙。
比如:有个编码代理,用来解决软件工程里的任务,代理我方先望望哪些文献需要改,然后反映出来,这么能大大进步成就的速率。
终末,第五部分里,Anthropic给出了一套成就器用的好点子,他们以为:
1. 器用在代理系统里杰出首要。它们能让代理和外面的处事、API好好相通;是以,器用蓄意和作念出来时要明晰分解,这么代理用起来才顺遂。
2. 成就者得给模子弥散的时分想考。别让模子在生成输出的时候卡壳,器用的输入模式和参数描述要阳春白雪,这么模子才能更好地交融和用这些器用。
3. 器用的界说和规格要和举座的提醒工程相似景仰。成就者要探讨不同模式对模子发扬的影响。比如:在裁剪文献时,不错选拔用互异模式或者重写通盘文献,要确保选的模式能让模子更容易生成正确的输出。
答复还建议要多作念测试,不雅察模子若何用器用,然后左证测试恶果不断矫正器用的蓄意,通过运行好多示例输入,成就者不错发现模子可能犯的极端,然后矫正。
终末,创建一个好的代理推断机接口(ACI)也很首要,成就者要确保器用用起来粗拙径直,这么用户体验才好;通过这些要领,Anthropic但愿能帮成就者在成就器用的时候避让常见的坑,确保代理系统能高效运行。
扫视:[1].Anthropic. Building effective agents. 2024.12.20;地址:https://www.anthropic.com/research/building-effective-agents
本文来自微信公众号:王智远,作家:王智远