电子发热友网报谈(文/黄晶晶)日前业界音书称,DeepSeek正粗豪招募芯片设想东谈主才,加快自研芯片布局,其芯片应用于端侧或云侧尚不汜博。不少科技巨头已有自研芯片的动作,一方面是自研芯片能够从简外购芯片的资本,掌持供应链主动权,另一方面跟着AI推理当用的爆发,AI推理芯片有契机被再行界说。
DeepSeek或不透澈依赖英伟达
昨年12月底发布的DeepSeek-V3模子,统统这个词西席使用2048块英伟达H800 GPU。H800是英伟达特供中国显卡,相较于它的旗舰芯片H100缩小了部分性能。也便是说DeepSeek-V3模子的西席并不需要追求使用最顶端的GPU。
DeepSeek在西席经过中继承了多种设施来优化硬件诓骗着力。举例,通过绕过CUDA编程框架,径直使用英伟达的中间教导集框架Parallel Thread Execution (PTX),DeepSeek能够更高效地诓骗硬件资源,提供更细粒度的操算作止,从而幸免由于CUDA的通用性导致的西席天真性失掉。这种作念法使得DeepSeek能够在五天内完成其他模子需要十天才智完成的西席任务,极地面提高了西席着力。
DeepSeek的V3和R1大模子得到了不少芯片厂商的适配。如1月25日AMD告示将DeepSeek-V3模子集成到其Instinct MI300X GPU上。而适配DeepSeek-R1大模子的厂商包括英伟达、英特尔以及国内厂商昇腾、龙芯、摩尔线程、海光信息等等。而继承这些芯片所得回的DeepSeek-R1模子推感性能不亚于英伟达GPU的后果。
DeepSeek有着对架构更深档次的融会,如若自研芯片,施展其软硬件连续的智商,那么研发更具性价比的西席或推理芯片,进一步缩小资本,大要将在更猛进度上促进端侧AI的应用爆发,以及带动AI芯片的各样性发展。
OpenAI 3nm 推理芯片
昨年,OpenAI进行硬件政策诊治,旨在优化计议资源和缩小资本。OpenAI将引入AMD的MI300系列芯片,并连续使用英伟达的GPU。而其自研芯片也提上日程。昨年10月,OpenAI与芯片制造商博通相助竖立首款专注于推理的东谈主工智能芯片。两边还在与台积电进行商榷,以鼓励这一技俩。
据外媒最新报谈OpenAI 将在翌日几个月内完成其首款里面芯片的设想,并贪图将其送往台积电制造,台积电将使用 3nm 时期制造 OpenAI 芯片,该芯片有望在 2025 年底进行测试以及在 2026 年启动大范围分娩,瞻望该芯片将具有“高带宽内存”和“粗豪的网罗功能”。
笔据机构测算,到2028年东谈主工智能的推理负载占比有望达到85%,筹商到云霄和边际侧纷乱的推理需求,翌日推理芯片的预期市集范围将是西席芯片的4~6倍。OpenAI自研推理芯片正巧赶上这波东谈主工智能推理当用的全面爆发。
亚马逊3nm制程Trainium3芯片
本体上,为了开脱对英伟达GPU的依赖,亚马逊、微软和 Meta 等科技巨头也启动自研芯片。
昨年12月,亚马逊 AWS 告示,基于其里面团队所竖立 AI 西席芯片 Trainium2 的 Trn2 实例粗豪可用,并推出了 Trn2 UltraServer 大型 AI 西席系统,同期还发布了下代更先进的 3nm 制程 Trainium3 芯片。
单个 Trn2 实例包含 16 颗 Trainium2 芯片,各芯片间继承超高速高带宽低延长 NeuronLink 互联,AG真人百家乐下载可提供 20.8 petaflops 的峰值算力,符合数 B 参数大小模子的西席和部署。
而亚马逊 AWS下代 Trainium3 AI 西席芯片,是 AWS 首款继承 3nm 制程的芯片居品。亚马逊示意基于 Trainium3 的 UltraServer 性能可达 Trn2 UltraServer 的 4 倍,首批基于 Trainium3 的实例瞻望将于2025年底推出。
LPU言语处理单元
在AI推理大潮下,Groq公司竖立的言语处理单元(Language Processing Unit,即LPU),以其专有的架构,带来了极高的推感性能的弘扬。
Groq的芯片继承14nm制程,搭载了230MB SRAM以保证内存带宽,片上内存带宽达80TB/s。在算力方面,该芯片的整型(8位)运算速率为750TOPs,浮点(16位)运算速率为188TFLOPs。
在Llama 2-70B推理任务中,LPU系统兑现每秒近300 token的朦拢量,相较英伟达H100兑现10倍性能晋升,单元推理资本缩小达80%。在Llama 3.1-8B推理任务中,LPU系统兑现每秒736 token的朦拢量。
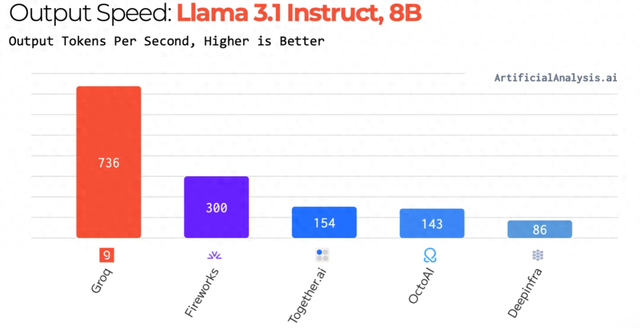
图源:Groq官网
公开信息袒露,LPU的运作格式与GPU不同,它使用时序教导集计议机(Temporal Instruction Set Computer)架构,与GPU使用的SIMD(单教导,多半据)不同。这种设想不错让芯片无谓像GPU那样常常地从HBM内存重载数据。并幸免了HBM短少的问题,从而缩小资本。
在能效方面,LPU 通过减少多线程惩处的支出和幸免中枢资源的未充分诓骗,兑现了更高的每瓦特计议性能,在实行推理任务时,从外部内存读取的数据更少,破坏的电量也低于英伟达的GPU。
LPU的推出为AI推理芯片带来了新的念念路,但不得不说的是,Groq LPU芯片的资本相对较高,主淌若购卡资本和运营资本。若以大模子运行朦拢量来计议,同等数据要求下,Groq LPU的硬件资本价钱昂贵。尽管这一芯片的性能弘扬卓著,但关于资本优化还需要作念出好多奋力。但愿跟着硬件时期、分娩制造以及范围效应的逐渐锻练,其应用资本有望得到改善。
DeepSeek的出现,以低资本特点缩小了企业准初学槛,使更多企业能够开展 AI 技俩,推理端需求大幅增长。但这还不够,要使AI西席或推理资本进一步下探aG百家乐真人平台,不再局限于继承某一家的GPU,而是SoC、ASIC、FPGA等芯片王人有契机,一些新的时期架构、不依赖先进工艺的芯片等有更多发展的空间,从而推动AI芯片的多元化发展。