
图灵奖得主杨立昆以为,当今AI界捏续追捧的大言语模子并非十全十好意思,它荫藏着四个难以卤莽的致命瑕玷:一是判辨物理寰宇,二是领有捏久挂念,三是具备推理才气,四是复杂缱绻才气。
而能够克服第一个“致命瑕玷”的技能,叫作寰宇模子。

这听起来简略很抽象,但你一定知谈谷歌的3D游戏、特斯拉的自动驾驶。
寰宇模子意味着机器能够像东谈主相同永诀物理空间、判辨物理规矩、凭据教训作念出推理决策。
与大言语模子不同的是,寰宇模子不再罢职从海量文本语料生成概率的逻辑,而是在深度分析大领域实验寰宇视频后推测因果。
就像东谈主类寰宇的婴儿相同,在交互学习中构建对这个寰宇的融会。

思象一个刚降生的婴儿,她的眼睛尚未全王人聚焦,却能通过触摸、温度、声息的碎屑凑合出寰宇的笼统。东谈主类大脑用数百万年进化出这种才气——将感官信息调整为对物理规矩的判辨。
而这正是今天东谈主工智能所欠缺的,寰宇模子正在起劲发展的——从数据中重构对重力、时刻等知识的判辨。
寰宇模子的见地最早可回顾至1980s到1990s的融会科学和末端表面,其时的参议者受心绪学影响,提议AI系统需要构建对环境的里面模拟,从而进行计议和决策,即AI的环境建模才气。
这里有一个进击的身分:环境。
从生物学上来讲,不管是微生物、动物照旧东谈主,步履王人罢职着一个最基本的端正:刺激-反应模式,即生物反应是对环境刺激的径直反馈。

跟着生物千亿年漫长的进化,动物发展出感觉和心绪,通过视觉、听觉、感觉等感官感知外界,产生出喜跃、怯怯等浅近情感;东谈主类进一步发展出自我结实,而东谈主类结实和动物感觉最大的区别是能否自主缱绻、有办法地进行决策和举止。
拿生物进化经过和AI的发展历程比较,咱们不难发现,其实AI的终极景色AGI等于要发展出自主感知实验、自我缱绻、有办法决策的才气。
寰宇模子的雏形就萌芽于心绪学家对东谈主类和动物融会判辨寰宇并作念出决策的不雅察。这个表面叫作心智模子,1990年由David Rumelhart提议,强调智能体需对环境造成抽象表征。
以咱们本身例如,东谈主类大脑对周围寰宇有一种习得的内在融会框架,凭据教训作念决策,如看到乌云就联思到下雨。再比如,咱们不会记着每片树叶的神志,却能蓦的判断树枝能否承受体重。同理,寰宇模子等于让机器构建起对周围环境和寰宇的判辨和计议才气,比如看到火就联思到烫伤。这种抽象才气,正是这一时期学者但愿机器用有的天禀。
然则,这阶段的寰宇模子参议停留在表面构思阶段,虽有了较为了了的界说和方针,仍莫得具体的技能旅途。

寰宇模子参议运行落地是2000s到2010s的计较建模阶段,跟着强化学习和深度学习的长远发展,学者运行尝试用神经集聚构建可试验的寰宇模子。
强化学习通过赏罚机制让其在与环境交互经过中不停习得计谋,雷同于“训狗”,深度学习通过分层特征索要让其从海量数据中自动学习规矩,雷同于“真金不怕火金”。
2018年,DeepMind 《World Models》(Ha & Schmidhuber)论文初度用“VAE+RNN+末端器”的三段式架构,构建可计议环境的神经集聚模子,成为当代寰宇模子的里程碑。
这仍是过雷同于“造梦”——先通过自动编码器VAE将实验场景压缩成数据,再行使RNN轮回神经集聚推演改日可能的情节,临了用精简的末端器带领举止。这意味着寰宇模子初度具备了颅内推演的才气,像东谈主类相同在举止前预判后果,大大裁汰了试错资本。
2022年后,寰宇模子插足大模子期间,借助Transformer的序列建模才气和多模态学习技能,应用范围从单一模态扩张到跨模态仿真,寰宇模子的推演也从2D走向3D(如OpenAI的GATO、DeepMind的Genie)。

近期参议如Meta的VC-1、Google的PaLM-E进一步将寰宇模子的见地带入公众视线,将寰宇模子与大言语模子结合以已毕更通用的环境推理成为一种技能发展旅途。
Google的PaLM-E(5620亿参数)模子见效将言语模子与视觉、传感器数据等物理寰宇信息结合,机器东谈主能够判辨复杂教导(如“捡起掉落的锤子”)并稳当新环境实施任务。Meta Llama系列的开源多模态框架(如MultiPLY)进一步促进了对物理环境的3D感知参议。
由上,从见地推演到落地实践,寰宇模子在发展中迟缓摸索,缓缓走出一条从蒙胧到直率的路。

Transformer架构的进化、多模态数据的爆发,让寰宇模子走出试验场,走进游戏场,再走向着实寰宇——谷歌、腾讯通过其生成传神的游戏场景,特斯拉用神经集聚计议车辆轨迹,DeepMind通过建模计议巨匠天气。
就这么,在实验室中踉跄学步的寰宇模子运行了他对实验物理规矩的探索之路。
就像东谈主类少小通过游戏感受端正完成社会化相同,寰宇模子的第一关亦然游戏。
初期的模子应用仰赖端正明确的编造环境和界限了了的破碎空间,如Atari游戏(DQN)、星际争霸(AlphaStar),剿袭表格型模子(如Dyna),后期结合CNN/RNN惩处图像输入。

进化至3D版后,ag百家乐可以安全出款的网站谷歌DeepMind的Genie 2可通过单张图片生成可交互的无穷3D寰宇,时长达1min,用户可目田探索动态环境(如地形变化、物体互动)。由腾讯、港科大、中国科大诱骗推出的GameGen-O模子可一键生成西部牛仔、魔法师、驯兽师等游戏变装,还能以更高保真度、更复杂的物理拒绝生成海啸、龙卷风、激光等各式场景。
经过大王人试验后,寰宇模子由游戏过渡到工业场景。
游戏引擎的中枢才气在于构建高保真、可交互的3D编造环境。这种才气被径直迁徙到工业场景中,用于模拟工业场景中各式可能出现故障的复杂场景。

机器东谈主公司波士顿能源在编造环境中预演机器东谈主手脚(如跌倒复原),再迁徙到实体机器;特斯拉2023年提议的寰宇模子径直整合了游戏引擎的仿真技能,行使合成数据试验自动驾驶系统,减少对着实路测数据的依赖;蔚来的智能寰宇模子能够在极短时刻内推演数百种可能情境并作念好预案和决策。
最近,寰宇模子还走进了基础参议领域。
DeepMind的GraphCast靠寰宇模子惩处百万级网格骄傲变量,计议天气才气比传统数值模拟快1000倍,能耗裁汰1000倍。它通过图神经集聚架构,能够径直从历史再分析数据中学习天气系统的复杂能源学,精确、高效计议巨匠天气。
从游戏般的编造场景到自动驾驶等实验场景,寰宇模子的本色是通过大王人多模态贵寓判辨物理寰宇的规矩。改日,“寰宇模子+大言语模子”可能成为AGI的中枢架构,让AI不仅能聊天,还能着实判辨并作念出决策改造实验寰宇。
不外,咱们为何需要寰宇模子?在大言语模子火爆巨匠的今天,是什么让其显得不能替代呢?

让AI着实从师法表征到感知本色,克服其各式恐怖谷效应的关节是:让它着实判辨这个寰宇,了解实验空间和物理规矩,进而判辨它为什么会作念这件事,而不是机械地凭据海量数据的联系概率推测下一个token是什么。
这是基于大领域文本语料的大言语模子和不停试错优化寻找最优旅途的强化学习作念不到的,独一生界模子能作念到。
传统AI是数据驱动型的被迫反应系统,而寰宇模子通过构建里面编造环境判辨了物理、碰撞等实验规矩,能够像东谈主类相同通过思象预演举止后果,并在游戏、机器东谈主等领域分享底层推理算力。
当先是通过底层建模和多模态整合构建出跟东谈主类相同的心智模子。外部,寰宇模子不仅模拟物理规矩,还试图判辨社会端正和生物步履,从而在复杂场景中违害就利。里面,寰宇模子凭据感知、计议、缱绻和学习的协同,造成雷同东谈主类心智的时空融会才气。

其次是因果计议和反事实推理才气。寰宇模子能够基于刻下情状和举止,计议改日的演变拒绝。其具备雷同东谈主类的学问库,能填补缺失信息并进行反事实推理(what if),即使未径直不雅察某事件,也能推断“如若选拔不同业动会如何”。这种才气使其在数据稀缺时仍能灵验决策,减少对海量标注数据的依赖,在自动驾驶领域应用较多。
临了,寰宇模子通过自监督学习构建对寰宇的通用表征,取得了跨任务、跨场景的泛化才气,而传统模子不时需针对特定领域的具体任务微调。
然则,这些才气,为什么火极一时的大言语模子作念不到呢?
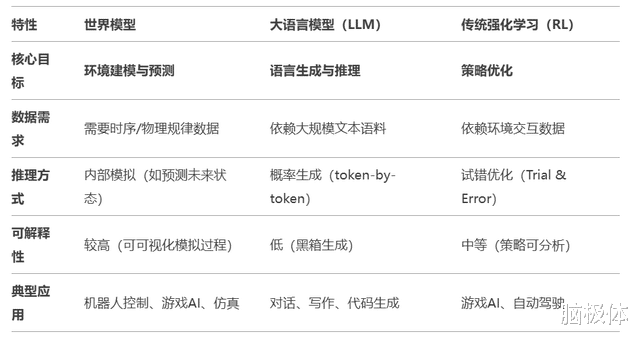
要弄清为什么寰宇模子的计议才气和大言语模子的推测token才气不相同,咱们需要弄清一个见地:有关性≠因果性。前者是概率联系、后者是因果推理。
大言语模子(如GPT系列)侧重于大数据驱动的自转头学习,通过海量文本数据试验模子以生成文本,本色是计议概率,而寰宇模子宗派以为自转头的Transformer无法通往AGI。AI需要具备着实的学问性判辨才气,这些才气只可通过深度分析大王人像片、音视频等多模态数据对寰宇的内在表征来取得。
模子结构层面,大言语模子主要依赖Transformer架构,通过自提防力机制惩处文本序列。寰宇模子则包含多个模块,如树立器、感知、寰宇模子、变装等,能够臆度寰宇情状、计议变化、寻找最优有辩论。
等闲地讲,大言语模子试验出的文本天才是聊以自慰的文将,对学问可能一窍欠亨。而寰宇模子更像在建模环境里转斗千里的武将,不错凭直观和教训预判敌手如何出招。

寰宇模子虽远景可期,当今依然濒临着一些瓶颈。
算力上,试验寰宇模子所需要的计较资源远超大言语模子,且存在“幻觉”(子虚计议)问题;泛化才气上,如何均衡模子复杂度与跨场景稳当性仍需卤莽;试验集上,多模态的数据领域更少,且需深度标注,质料把关是重中之重。
如若说雷同GPT相同的大言语模子已经到了滔滔赓续的芳华期,寰宇模子实则还处于牙牙学语的少小期。
总的来讲,寰宇模子是深度学习以外的另一条探索谈路。如若改日深度学习堕入发展瓶颈,寰宇模子可能是一种备选有辩论。但现阶段,寰宇模子仍在探索期,咱们仍要将顶梁柱放在大言语模子和深度学习这条技能线上。
多点发力,协同并进,才能让AI的成长有更多谈路可走。
 AG真人旗舰厅百家乐
AG真人旗舰厅百家乐