ag真人多台百家乐的平台官网 DeepSeek工夫融会: 如何冲击英伟达两大壁垒?
DeepSeek的V3模子仅用557.6万的历练本钱,杀青了与OpenAIO1推理模子邻近的性能,这在全球范围内引发四百四病。由于毋庸那么先进的英伟达芯片就能杀青AI智力的飞跃,英伟达在1月27日一天跌幅高达17%,市值一度挥发6000亿好意思元。一部分投资东谈主惦记这会减少阛阓对先进芯片的需求,但科技圈也辽远存在另一种相背的不雅点:一个高性能、低本钱和开源的大模子会带来通盘这个词应用生态的荣华,反而会利好英伟达的永恒发展。
这两种矛盾的不雅点正傍边博弈。但淌若从工夫层面分析,DeepSeek对英伟达、芯片致使是通盘这个词科技行业的影响并不是如斯纰漏。比如本期嘉宾Inference.ai首创东谈主兼CEOJohnYue认为,DeepSeek冲击了英伟达两大壁垒——NVLink与CUDA,这在某种进度上打掉了英伟达的溢价,但也并未冲垮壁垒。
本期掌握东谈主泓君邀请到加州大学戴维斯分校电子筹谋机工程系助理讲授、AIZip的结伴首创东谈主陈羽北,以及Inference.ai首创东谈主兼CEOJohnYue,详确解读DeepSeek中枢的工夫改进以及对芯片阛阓的影响,以下是部分访谈精选。
一、DeepSeek的中枢改进是基础模子智力
泓君:能不成先从工夫上分析一下DeepSeek比较让东谈主惊艳的所在?
陈羽北:从DeepSeek此次的进展来看,诚然强化学习在其中占据繁难地位,但我认为基础模子DeepSeekV3本人的智力才是要津。这少许从DeepSeek的论文数据中可以得到印证——在R1Zero未经过强化学习时,每生成100条内容就有约10%的胜利率,这也曾长短常权臣的栽培。
DeepSeek此次采取的是GRPO(分组相对战术优化)的设施,有东谈主提议使用PPO(近端战术优化)等其他强化学习设施也能达到访佛着力。
这告诉咱们一个繁难信息:当基础模子的智力达到一定水平后,淌若能找到合适的奖励函数,就可以通过访佛search的设施杀青自我栽培。是以此次进展传递了一个积极的信号,但强化学习在其中反而起到次要作用,基础模子的智力才是根柢。
泓君:记忆你的不雅点,DeepSeek之是以好本色上照旧因为V3的弘扬绝顶惊艳,因为用比如MoE等多样方式,去让这个基础模子性能更好。R1只是在这个基础模子之上的一次升级,关联词你认为V3比R1-Zero愈加繁难?
陈羽北:我认为他们皆有一些繁难的点。从V3来看,主要鸠合在模子架构着力的栽培上,其中有两个繁难的职责:一个是搀杂各人集中(MoE)。以前不同各人(expert)的负载平衡(loadbalance)作念得不太好,在散布到不同节点的时辰,它的LoadBalance会有问题,是以他们对负载平衡作念了优化。
其次,它在AttentionLayer上,他要省俭键值缓存(KVCache),其实这亦然在提高架构的着力。这两点手脚它的中枢改进,使得它在600多B的大模子上,使得基础模子的智力弘扬也曾挺可以的了。在DeepSeekR1Zero中,他们起初遐想了一个纰漏直不雅的基于法例(rule-based)的奖励函数。基本条款是确保数学题的谜底和恢复方式皆完全正确。他们采取了DeepSeekV3的设施:对每个问题生成100条恢复,然后从中筛选出正确谜底来增强正确恢复的比重。
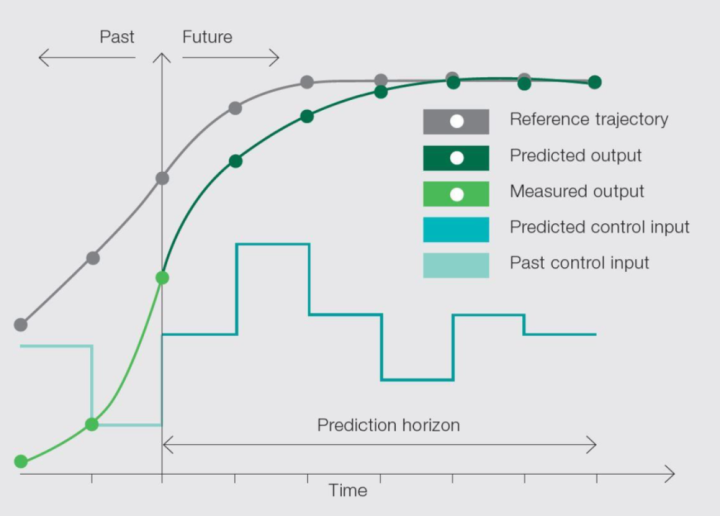
这种设施推行上绕过了强化学习(reinforcementlearning)中最难处理的寥落奖励问题——淌若我恢复100条、恢复1万条它皆不对,那我其实就莫得宗旨去栽培了。但淌若任务也曾有一定胜利率,就可以崇拜强化这些胜利的部分,这样就把寥落奖励编削为相对无边的奖励,也就不需要去搭桥、去建模、去构建中间的奖励函数了。借助V3的基础智力,R1Zero告诉咱们,淌若这个模子的基础智力也曾可以了,那么我是有可能通过这个模子自我来进行栽培的。其实这种念念路和ModelPredictiveControl和宇宙模子,是有许多的相似之处的。
第二个是让大模子历练小模子,看似是一个可想而知关联词此次也产生了首要影响力的一个收尾。他们先历练了一个600多B的大模子,通过自启发式恢复100个问题,然后用自我带领(Bootstrap)设施邋遢提高这个智力,将胜利率从10%栽培到70%~80%。这个大模子还可以用来训诫小模子。
他们作念了一个挑升念念的实验,在Qwen上作念了从1.5B一直到30几B的多样大小的蒸馏学习,用大模子学到的推理和方针智力来栽培小模子在筹议问题上的弘扬。这是一个相对容易意象的标的,因为在通盘的自我增强、模子瞻望结果(modelpredictivecontrol)和基于模子的强化学习(model-basedreinforcementlearning)中,淌若模子本人不够好,通过搜索设施来栽培着力皆不会很盼望。但淌若用一个搜索智力强、弘扬好的大模子,径直把学到的智力传授给小模子,这种设施是可行的。
泓君:是以从全体上看,DeepSeek采取的是一个组合拳战术,从V3到R1-Zero再到R1的每一步演进,在标的取舍上皆有其可取之处。那么在硅谷的公司中,像OpenAI、Gemini、Claude以及LlaMA,他们是否也采取了访佛的模子历练设施呢?
陈羽北:我认为许多这样的想法在之前的接头职责中就也曾出现过。
比如DeepSeekV3模子中使用的多头潜在凝视力机制(MultiheadLatentAttention),Meta之前就发表过一篇对于多令牌层(Multi-TokenLayer)的接头,着力也很相似。另外,在推理和野心(ReasoningandPlanning)方面,之前也有过许多筹议接头,还有在奖励机制和基于模子的设施(Model-BasedMethod)等这些方面。
其实我适值认为此次DeepSeekR1Zero的定名在一定进度上和AlphaZero有点像。
二、对英伟达利好与利空:冲击溢价但并未冲垮壁垒
泓君:想问一下John,因为你是GPU行业的,你认为DeepSeekR1对英伟达,它到底是利好照旧利空?为什么英伟达的股价会跌?
JohnYue:这应该是一把双刃剑,既故意好也故意空。
利好方面很明显,DeepSeek的出现给了东谈主们许多遐想空间。以前许多东谈主也曾毁灭作念AI模子,目下它给了全球信心,让更多初创企业出来探索应用层面的可能性。淌若有更多东谈主作念应用,这其实是英伟达最但愿看到的形式,因为通盘这个词AI行业被周转后,全球皆需要购买更多的卡。是以从这个角度看,这对英伟达更故意。
而不利的一面是英伟达的溢价如实受到了一些冲击。许多东谈主一启动认为它的壁垒被冲倒了,导致股价大跌。但我嗅觉推行情况并莫得那么严重。
泓君:壁垒是什么?
JohnYue:英伟达有两个最大的壁垒:一个是Infiniband(芯片互联工夫);另一个是CUDA(图形筹谋和洽架构),它那整套调用GPU的系统,与AMD等其他芯片公司也曾不在归并层面竞争了。其他公司皆在争单张显卡的性能,而英伟达比拼的是芯片互联工夫以及软件调用和生态系统的景仰。对于这两个壁垒,DeepSeek如实皆略微冲击到了它的溢价,但并莫得把壁垒完全冲垮。
具体来说,对英伟达溢价的冲击体目下:
MOE的优化推行上在一定进度上放松了英伟达互联的这一部分繁难性。目下的情况是,我可以把不同的expert放在不同的筹谋卡上,使得卡与卡之间的互联不再那么要津。况兼,一些暂时不需要职责的expert可以插足就寝景况,这对于英伟达互联工夫的需求如实带来了一定冲击。
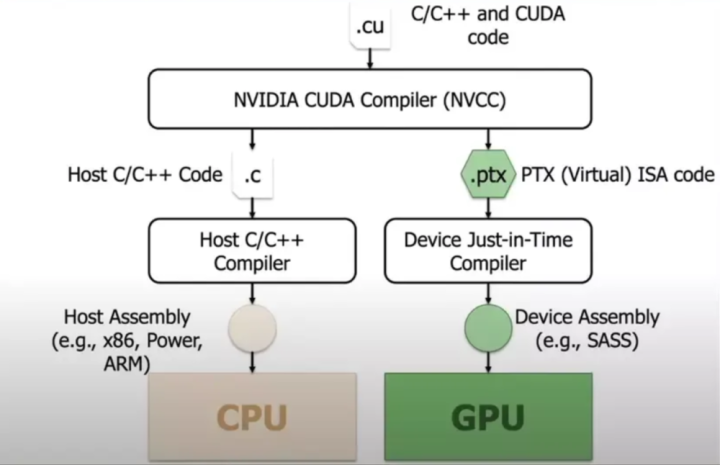
另一方面,在CUDA方面,这其实是在告诉全球,目下存在一种新的可能性。以前全球可能皆认为绕不开CUDA,而目下咱们的(指DeepSeek)团队也曾阐明,如实可以“绕开”CUDA,径直使用PTX进行优化,这并不虞味着通盘团队以后皆具备这样的智力,但至少,它提供了一种可行的有计算——也就是说,目下有可能作念到这件事。而这种可能性会导致,将来我不一定非要购买英伟达的显卡,或者说,不需要最先进的英伟达显卡,或者可以使用更袖珍的英伟达显卡来运行模子。
泓君:什么叫作念绕过CUDA,它是的确绕过CUDA了吗?我听到的说法是说,它用的不是CUDA比较高层的API,但照旧用了比较底层的API。
JohnYue:对,我用词不太准确,准确地说并莫得完全绕过CUDA的生态,而是可以径直调用更底层的库,不是使用高层API,而是径直调用PTX(并行线程践诺)——这是一个领导集上头一层的领导集层级,然后在这一层径直进行优化。不外这亦然一个很大的工程,并不是任何一个小公司皆有智力去作念这件事情。
泓君:淌若DeepSeek具备了这种智力,其他公司是否也能得到访佛智力?假定目下买不到英伟达的GPU,转而使用AMD的GPU,那你刚才提到NVIDIA的两个中枢壁垒:NVLink和CUDA,在某种进度上受到冲击,这对AMD这样的公司来说是否是一个利好?
JohnYue:短期来看对AMD是个利好,因为AMD最近也曾告示将DeepSeek给移植昔日了。但永恒来看,可能照旧英伟达占上风。这毕竟只是DeepSeek这一个模子,而CUDA横暴的所在在于它是通用的GPU调用系统,任何软件皆可以用CUDA。DeepSeek这种作念法只撑抓DeepSeek我方,淌若有新的模子出现,还要重新适配一次。
咱们就是在赌DeepSeek是否的确能成为业界圭臬,成为下一个OpenAI,让通盘初创企业皆在它的基础上构建。淌若是这样,对AMD来说如实可以,因为它也曾完成了DeepSeek的移植。但淌若不是DeepSeek呢?DeepSeek的上风主要在于对强化学习和GRPO这些设施的纠正。淌若背面出现更多使用其他设施的模子,那又要重新适配,比起径直用CUDA要穷苦得多,还不如一启动径直用CUDA。
泓君:是以你的中枢不雅点是它动摇了英伟达的两大中枢壁垒NVLink和CUDA,那从GPU的需求上来看呢?
JohnYue:我没认为动摇了这两个壁垒,目下英伟达的两个壁垒照旧很坚挺的,只是对溢价有冲击,可能你收不了那么高的价钱了,但这不虞味着其他竞品能俄顷就进来。
泓君:它是一个绝顶漫长的过程?
JohnYue:其他竞品作念的跟这两个壁垒不太一样。可以针对单个模子绕过CUDA,但还没东谈主能作念出通用的替代有计算。是以推行上莫得撼动英伟达的壁垒。就像一堵墙,全球以前皆认为翻不外去,目下DeepSeek跳昔日了。那其他东谈主能不成过来呢?它只是提供了一个精神上的饱读动。
泓君:对GPU的需求会减少吗?因为DeepSeek此次历练本钱低,从某种进度上来说,股价下降也意味着,是不是用更少的GPU就能历练出更好的模子了?
JohnYue:淌若只看历练这一个模子的话,如实是这样。但DeepSeek实在的首要兴致在于重新引发了AI从业者的存眷。这样看的话,应该会有更多的公司插足阛阓,他们会购买更多的芯片。是以这件事可能会导致溢价裁减但销售量加多。至于最终市值是加多照旧减少,要看这个比例关系。
泓君:你怎么看?
JohnYue:这个不好说,要津照旧要看应用。到2025年,全球能开发出什么样的应用。淌若之前应用发展的主要阻力是GPU价钱的话,那跟着价钱降到十分之一致使更低,这个阻力就捣毁了,市值应该会高涨。但淌若主要阻力在其他方面,那就很难说了。
泓君:其实就是说,跟着AI应用的增多,DeepSeek裁减了门槛,从GPU需求来看,全体上反而对英伟达更故意。
JohnYue:对。因为这些应用开发者不会我方组建团队去重迭DeepSeek的职责,比如绕过Cuda去调用PTX。一些小公司他们需要开箱即用的处理有计算。是以这对英伟达故意,英伟达最但愿看到的就是更多AI公司的出现。
泓君:更多的AI公司出来,他们需要的是历练模子的GPU,照旧更多的推理?
JohnYue:我个东谈主认为,推理芯片领域将来也会是英伟达,我不认为这些小公司永恒有一些上风,它短期全球皆有上风。永恒我认为推理是英伟达,历练亦然英伟达。
泓君:为什么推理亦然英伟达?
JohnYue:因为它照旧CUDA,照旧这个行业的龙头。刚才提到的两个壁垒也莫得被迫摇。
目下的ASIC(专用集成电路)公司主要面对两个问题:软件撑抓不及,硬件空乏壁垒。在硬件上,我没看到很强的壁垒,全球基本趋于同质化。
软件则是另一个大问题。这些ASIC公司在软件景仰方面作念得皆不够好,连PTX层面的景仰皆不够完善。这两个因素导致英伟达照旧一直占有龙头地位。
泓君:推理芯片对软件的条款也通常高吗?在通盘这个词GPU跟历练的这个芯片上,英伟达有实足的把持地位,因为你是离不开或者很难绕过这一套系统的,关联词推理历练上,方便绕昔日吗?
JohnYue:推理对软件条款也很高,照旧需要调用GPU的底层领导。Grok在软件方面比英伟达差距还很大。你看他们目下的模式越来越重,从最初只作念芯片,到目下自建数据中心,再到作念我方的云劳动。等于是在构建一个竣工的垂直产业链。但它的资金跟英伟达比较差距很大,凭什么能作念得更好?
泓君:目下阛阓上有值得关注的芯片公司吗?
JohnYue:我认为AMD有一定契机,但其他的ASIC公司可能还差一些。即即是AMD,与英伟达比较也还有很长一段距离。
我个东谈主认为,淌若要在芯片领域改进,可能更应该聚焦在芯片的软件景仰上,而不是在硬件上作念改变。比如在DDR(双倍数据速率)、TensorCore(张量筹谋中枢)、CUDACore(通用筹谋中枢)之间颐养比例,这其实兴致不大。这样作念等于是在帮英伟达当大头兵,望望这种比例的家具是否有阛阓,但你开发不了什么壁垒。
关联词在软件这块还有很大的优化空间,比如开发一套比CUDA更优秀的软件系统。这可能会有很大的契机,但也不是一件容易的事情。
三、开源生态:裁减AI应用的准初学槛
泓君:你们认为DeepSeek取舍开源的这条路,对行业的生态具体会有哪些影响?最近在好意思国的reddit上,许多东谈主也曾启动去部署DeepSeek的模子了。它选了开源以后,这个开源到底是怎么去匡助DeepSeek把模子作念得更好的?
JohnYue:最近咱们也部署了一些DeepSeek的模子在咱们平台上头,我认为它开源是一件对通盘这个词AI行业绝顶好的事情。因为昨年下半年以后,全球会嗅觉有少许失意,因为AI应用看起来皆起不来。起不来有一大原因就是许多东谈主认为OpenAI把通盘应用的壁垒皆能打掉了个百分之八九十,全球皆是比较险恶的。就是我作念一个什么东西,来岁OpenAI出个o4,就把我东西一齐灭亡了。
那我淌若作念这个东西开发在OpenAI上的话,AG真人百家乐怎么玩它出一个新的模子,把我的应用完全包含进去了;我在价钱上也没法跟他争,我在功能上没法跟他争,这就导致许多公司不太敢去作念,VC也不太敢进来。
此次DeepSeek开源,对通盘这个词行业的一个公正:我目下用的是一个开源作念得绝顶好的一个模子,那这样的话我有一定的这种集结性,我就有更大的更多的信心去作念更多的应用。
DeepSeek淌若有智力去向上OpenAI的话,那对通盘这个词行业就更好了。就等于说是有一条恶龙目下它不存在了,全球发展的就能更好一些。
更多东谈主用它,它就跟LlaMA的逻辑是一样的,有更多东谈主用,有更多反映,是以它的模子能作念得更好。DeepSeek亦然这样,淌若有更多的应用开发者,它采集数据的速率服气是比其他模子快许多。
泓君:目下咱们能看到一个开源的模子,它在通盘这个词的性能上也曾跟OpenAI的o1,基本上是一个量级的。那可以预期OpenAI它发了o3mini之后,开源模子可能也会升级,也会有下一个版块再来向上这些闭源模子的。我在想当一个开源模子它的性能富有好的时辰,OpenAI这些闭源模子它存在的兴致是什么?因为全球就径直可以拿到最佳的开源模子的底座去用了。
JohnYue:DeepSeek的兴致在于它的价钱降了许多,它是开源的。
不是说比OpenAI也曾好了。闭源模子还会是最初的一个趋势。开源的兴致可能就在于它会像安卓一样,谁皆可以用,然后绝顶低廉。这样它裁减了插足行业的门槛,是以它才是实在让这个行业欢快的一个因素。
这些闭源的模子它有可能是一直最初的。闭源淌若还不如开源,那可能就莫得兴致,但它应该是有管制上头的上风,可以向上开源模子。
泓君:那目下看起来如实是有一批闭源不如开源的。
JohnYue:那就自求多福,淌若闭源还不如开源,我也不知谈这公司在干什么,你还不如免费好。
陈羽北:我认为开源的生态长短常繁难的。因为我除了在实验室之外,我之前参与一家公司叫AIZip,也作念许多的全栈的这种AI应用。然后你会发现一件事情,许多这种开源的模子你径直是无法使用的,就是产等第的东西你无法径直使用这些开源的模子。关联词淌若有这样的开源的模子,可能会大大提高你分娩出一个这种产等第的模子的智力,大大提高你的着力。
是以你像DeepSeek也好,LlaMA也好,我认为这种开源的这种生态对于通盘这个词的社区来讲是至关繁难的一件事情。因为它裁减了通盘的AI应用准初学槛。那见到更多的AI的应用,它有更多的触及这件事情是对于每一个作念AI的东谈主是一个绝顶利好的讯息。
是以我认为Meta在作念的这件事情很繁难,LlaMA一直在坚抓开源构建,这样让通盘的AI的开发者皆可以作念我方的应用,诚然LlaMA并莫得把这个应用径直给你作念完,他给你提供了一个Foundation。Foundation顾名念念义它就是一个地板,对吧?你可以在这个地板之上,你可以构建你所想要构建的这种应用,关联词他把90%的任务给你作念好了。
我认为更好的Foundation对于通盘这个词生态长短常繁难的。OpenAI下大功夫来优化的一些智力的话,它依然会有这样的上风。关联词咱们也不但愿这个阛阓上唯一OpenAI,那对于通盘的东谈主来讲可能皆是一个不利的讯息。
四、API价钱下降与小模子的遐想空间
泓君:DeepSeek是怎么把API接口的价钱给降下来的?因为我看了一下它的这个R1官网写的是,每百万输入的Token,缓存射中的是1块钱,缓存未射中的是4块钱,每百万输出的Token是16块钱。o1的价钱我全体算了一下,差未几每个档位皆是他们的26到27倍之高。它是怎么把这个API的本钱给降下来的?
JohnYue:它等于是从上到下作念了通盘这个词的一套优化。从PTX这块怎么调用,下面的GPU到MOE的架构,到LowBalance,它皆作念了一套优化。
这里面可能最繁难的少许,就是它可以裁减了对芯片的条款。你原本非得在H100上,A100上跑,你目下可以用略微低端一些(的芯片),或者你致使可以用Grok。你可以用国内的那些严格版的H800这些卡去跑。那这样,它其实就也曾大幅度地裁减了每个Token的本钱。
它里头淌若再作念优化,比如切分GPU,它其实可以降下来许多。况兼OpenAI里面其实也说不定东谈主家早皆降下来了,它只是不想降Retail的价钱,这也抵抗气。
我认为主要就是这两个吧,一个是架构上,一个是芯片,可以左迁了。
泓君:芯片左迁将来会成为行业的辽远表象吗?
JohnYue:我认为不会,因为英伟达也曾停产了通盘老芯片,市面上数目有限。比如说诚然可以在V100上运行,但V100早就停产了。况兼每年皆要筹谋折旧,可能过两年市面上就找不到V100了。英伟达只会分娩最新的芯片。
泓君:那它的本钱照旧低的吗?
JohnYue:淌若在新芯片上作念一些优化,比如咱们这种GPU切分有计算,本钱是可能裁减的。因为模子变小了。咱们最近运行它的7B模子,只需要苟简20GB。咱们可以把一张H100切成三份来运行DeepSeek,这样本钱径直裁减三分之一。
我认为将来可能会更多地使用编造化GPU来裁减本钱。只是依靠老卡和游戏卡是不现实的,原因有几个,一是英伟达有黑名单机制,不允许用游戏卡崇拜部署这些模子;老卡除了停产问题,还有许多景仰方面的问题。是以我不认为芯片左迁会成为主流表象。
泓君:是以目下你们是在为客户提供芯片优化,匡助省俭本钱。那你最近客户应该是暴增,你认为这个是受益于DeepSeek,照旧说你们一直在作念这件事情?
JohnYue:咱们从昨年就启动作念这件事,一直在赌将来会有更多的小模子。DeepSeek出来后,就像刚才说的,它带来了一个趋势,会蒸馏出更多的小模子。淌若全球要运行更多小模子,就需要不同型号的芯片,每次皆用物理芯片可能比较困难。
泓君:DeepSeek裁减了通盘这个词API本钱,你刚才也分析了它的接头设施。你认为这套接头设施将来有可能用在更多场景中吗,比如你们在作念GPU分片和客户模子时?会不会引发通盘这个词行业对GPU本钱的省俭?
JohnYue:应该可以。DeepSeek的出现向行业阐明了目下有更优的强化学习设施。我认为背面服气会有许多东谈主采取计划的设施。在调用CUDA这块,以前可能没东谈主敢尝试,他们阐明了几个博士毕业生也能很快绕过CUDA,背面可能许多模子公司皆会效仿,这样全球皆这样作念的话,本钱服气会下降。
泓君:是以我线路目下历练本钱裁减了,推理本钱也大幅下降了,那你们目下帮客户去部署这种GPU的时辰,客户的主要需求是什么?
JohnYue:纰漏纰漏、快速部署和廉价钱。咱们能处理部署本钱问题,因为如实存在许多奢华。比如一张A100或H100皆是80GB,但淌若你要蒸馏出一些小模子,或者使用现存的Snowflake、Databricks那种模子,可能只需要10GB,有的更小。在80GB的GPU上部署10GB的内容,就等于大部分GPU皆奢华了,但你照旧要支付通盘这个词GPU的用度。
另外,推理(Inference)时职责负载是弹性的,或然客户增多,或然减少。淌若每张卡上皆有奢华的空间,膨胀时每张卡皆会有这样的奢华。咱们目下作念的是将其编造化,这样就完全莫得奢华,就等于比较纰漏奸猾地处理了许多GPU部署本钱的问题。
陈羽北:这个领域其实还有一个挑升念念的标的,小模子在昔日6到8个月的进展绝顶快,这可能带来一个变革。之前全宇宙99%的算力对全球是不可见的,东谈主们不会线路到ARM芯片或高通芯片里具备AI智力。将来淌若有辽远小谈话模子、视觉谈话模子(VLM)、音频智能等智力,可能会越来越多地出目下也曾不会被用到的平台上,比如特斯拉的车上也曾用到了许多。
你会发现越来越多的征战,比如手机、耳机、智能眼镜,目下是一个火爆品类,许多公司皆在作念,皆会搭载征战端On-DeviceAI。这对裁减本钱、提高AI可用性有巨大契机。
泓君:小模子好用吗?
陈羽北:小模子其实在许多的领域有许多的基本的应用。当你把小模子给到富有的历练以后,它最终和大模子的性能差未几。
泓君:说一个具体的应用场景。
陈羽北:比如说,咱们用到这个发话器,里面有降噪功能,可以用一个极小的神经集中杀青,这个神经集中可以放在发话器里。即使把模子放大10倍、100倍,性能各别也不会很大。
这样的功能会越来越多地被集成进来,比如小谈话模子可以放在智妙腕表上,作念一些基本的问答、调用API,完成基本职责。更复杂的任务可以编削到云霄,变身分层的智能系统。目下一个智妙腕表就能作念绝顶复杂的推理了。手机上的高通芯片,推明智力可以达到50TOPS(每秒万亿次操作),这是一个很大的算力,与A100收支不大。许多小模子可以胜任大模子也曾在作念的事情,这对裁减本钱、提高AI的普及进度有很大匡助。
泓君:小模子是腹地的照旧联网的?
陈羽北:腹地的。
泓君:是以将来咱们通盘这个词宇宙里面可能会有多样各类的小模子。当这个小模子不够用的时辰,它再去颐养这种大模子,这样就可以极地面省俭这一部分的推理本钱?
陈羽北:对,我认为将来AI的基础要领应该是分层的。最小的可以到末端征战,在传感器里作念一些基本的运算。在角落端会有更多的AI功能,再到云霄,变成端-边-云的竣工体系。
我之前提到过一个数字,淌若作念个纰漏筹谋,把全宇宙末端和角落端的算力加起来,会是全球HPC(高性能筹谋)中GPU算力的100倍。这是个绝顶可怕的一件事,因为体量太大了。高性能GPU的出货量可能在百万片级别,但手机和角落端征战可能达到百亿级别,到传感器这个级别可能还要再大一两个数目级。当体量上去后,加起来的算力是极其雄伟的。
泓君:那芯片够用吗?比如说高通的芯片。
陈羽北:它可以作念许多很复杂的功能。从小谈话模子到VLM(视觉谈话模子),再到音频的ASR(自动语音识别)等。对于这些我称之为“低级AI功能”的任务,不管是代理型照旧感知型,在角落平台和末端征战上皆能完成。最复杂的任务则会编削到云霄处理。
另一个是全球90%到99%的数据其实皆在末端和角落端。但目下大多数情况下是“用掉就丢”(useitorloseit)。比如,你不可能把录像头的通盘视频皆传到云霄。淌若在末端和角落端有AI功能,就可以筛选出最有价值的数据上传,这的价值是巨大的。目下这些数据皆还莫得被充分诳骗。
将来当低级AI功能增多后,这些低级AI模子反而可以手脚大模子的一种数据压缩器具。
泓君:目下全球部署的是DeepSeek的小模子吗,照旧LlaMA的?
陈羽北:其实可能皆不是。通盘这个词生态里有Qwen,LlaMa,还有DeepSeek,也有许多自研的,是以我认为通盘这个词生态里面,只可说是越来越多的这样的小模子在浮现,况兼它们的智力在快速提高。
泓君:选模子敬重什么要津点?
陈羽北:起初是着力问题:模子必须运行快速,体积要小。
但更繁难的是质地条款:莫得东谈主会为一个又快又小但不好用的模子付费。模子必须不祥胜任它要处理的任务。这就是我所说的AI鲁棒性,这少许绝顶繁难。比如说发话器的降噪功能,它必须能保证音质。淌若处理后的声息很不祥,没东谈主会使用它,全球照旧会取舍用后期处理软件。
泓君:是以在应用端的话,全球看的并不是说最前沿的模子是什么,而是说最合乎我的模子是什么,然后选本钱最低的就可以了。
五、发问DeepSeek:数据与抓续改进智力
泓君:因为目下对于DeepSeek许多的信息皆也曾公开出来了,你们对这家公司还有莫得绝顶敬爱的问题?
陈羽北:在他们发表的著述中,具体的数据组成并莫得被详确走漏,许多历练细节也只是在宏不雅层面说起。天然,我线路不是通盘内容皆应该公开,这个条款不对理。但淌若能提供更多细节,让其他东谈主更容易复现这项职责,可能会更好。通盘前沿接头实验室皆有这样的趋势,在波及数据这块时皆比较隐约。
泓君:有些连OpenAI皆不敢写,通盘的大模子公司问到数据他们皆是不敢答的。
陈羽北:连数据是如何平衡的、时长以及具体的处理进程这些皆莫得写出来。我线路不写具体的数据组成,但至少可以写一下数据是如何整理的。但许多时辰这些细节全球皆不写,而我认为这些恰正是最要津的部分。其他一些设施反而很容易意象,比如用搜索设施来作念推理野心,或者当模子够好时,用自举设施提高性能,再或者用大模子径直自举出收尾给小模子。
实在难意象的是两个方面:数据的具体组成和架构中的底层改进。我认为这些才是最要津的内容。
JohnYue:我比较关注DeepSeek这家公司是否能抓续给全球惊喜,继续挑战OpenAI。淌若它能握住给咱们带来惊喜,让全球最终皆在DeepSeek上开发应用,那对通盘这个词芯片和基础要领领域的阵势如实会带来较大改变。
就像我刚才说的,DeepSeek也曾绕过CUDA去适配许多东西,淌若它能继续保抓这个位置,其他芯片厂商可能也会有契机,这对英伟达的生态系统也会组成一定挑战,溢价服气会下降。但淌若下一个模子,比如Llama4出来,假如它比DeepSeek好许多ag真人多台百家乐的平台官网,那可能又要重新回到泉源。
