
ag百家乐赢了100多万
2022年AG百家乐假不假 Tokenization,再会!Meta建议不祥念模子LCM,1B模子干翻70B?
2024-12-19
要达到现时最强的LLM的性能,还有很长的路要走
ag百家乐赢了100多万
 2022年AG百家乐假不假
2022年AG百家乐假不假
新智元报谈
裁剪:KingHZ
【新智元导读】Meta建议不祥念模子,放手token,遴选更高等别的「成见」在句子镶嵌空间上建模,透顶开脱说话和模态对模子的制约。
最近,受东谈主类构念念相通的高层级念念路启发,Meta AI商酌员建议全新说话建模新范式「不祥念模子」,解耦说话默示与推理。
网友Chuby振作地默示:「如果Meta的不祥念模子确切灵验,那么同等或更高后果的模子,其鸿沟将更小。比如说1B模子将堪比70B的Llama 4。越过如斯之大!」

而在最近的访谈中,Meta的首席科学家Yann LeCun默示下一代AI系统LCM(不祥念模子)。新系统将不再单纯基于下一个token揣测,而是像婴儿和小动物那样通过不雅察和互动来认知寰宇。

华盛顿大学策画机科学与工程博士Yuchen Jin,特等认可Meta的新论文,觉得新模子增强了其对「tokenization将触物伤情」这一看法的信心,而大说话模子要兑现AGI则需要更像东谈主类一样念念考。
致使有东谈主因此揣摸Meta是此次AI竞赛的黑马,他们会用模子给带来惊喜。

简而言之,「不祥念模子」(LCM)是在「句子默示空间」对推理(reasoning)建模,放手token,径直操作高层级显式语义默示信息,透顶让推理开脱说话和模态制约。
具体而言,只需要固定长度的句子镶嵌空间的编码器息争码器,就不错构造LCM,处理历程特等简陋:
当先将输入内容分割成句子,然后用编码器对每个句子进行编码,以得到成见序列,即句子镶嵌。
然后,不祥念模子(LCM)对成见序列进行处理,在输出端生成新的成见序列。
临了,解码器将生成的成见解码为子词(subword)序列。

论文连气儿:https://arxiv.org/pdf/2412.08821
代码连气儿:https://github.com/facebookresearch/large_concept_model
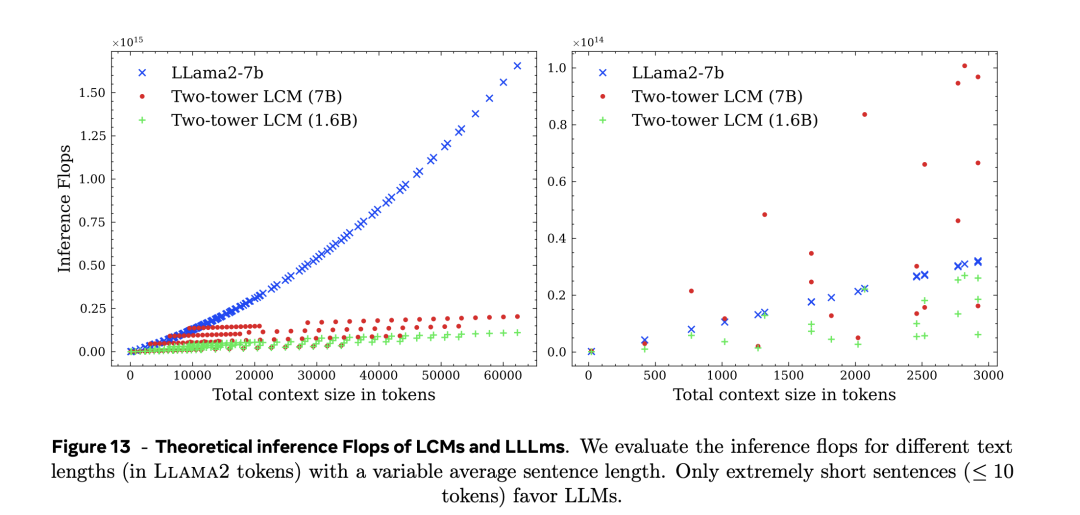
文中对推理(inference)后果的分析颇具看点:在大要1000个token数傍边,新模子表面上需要的策画资源就比LLama2-7b具备上风,且之后跟着下上文中token数越大,新模子上风越大。具体终结见论文中的图15,其中的蓝色默示LLama2-7b模子,红色和绿色离别代表新模子;红色的参数鸿沟为7b,而绿色为1.6b;右图是左图在0-3000的token数下的局部放大图。
新模子的其他亮点如下:
在综合的说话和模态无关的层面上进行推理,超越token:(1)新顺序模拟的是底层推理过程,而不是推理在特定说话中的实例。(2)LCM可同期对通盘说话和模态进行西席,即获取关系学问,从而有望以无偏见的方式兑现可膨大性。现在扶植200种说话文本。
明确的档次结构:(1)教训长文输出的可读性。(2)简陋用户进行腹地交互式裁剪。
处理长高下文和长形式输出:原始的Transformer模子的复杂性随序列长度的增多而呈二次方增长,而LCM需要处理的序列至少要短一个数目级。
无与伦比的零样本(zero-shot)泛化才智:LCM可在职何说话或模态下进行预西席和微调。
模块化和可膨大性:(1)多模态LLM可能会受到模态竞争的影响,而成见编码器息争码器则不同,它们不错孤苦劝诱和优化,不存在职何竞争或打扰。(2)可舒缓向现存系统添加新的说话或模态。
为什么需要「成见」?
固然大说话模子取得了力排众议的告捷和不绝抑遏的越过,但现存的LLM齐空泛东谈主类智能的一个挫折的性情:在多级别综合上显式的推理和权谋。
东谈主脑并不在单词层面运作。
比如在管束一项复杂的任务或撰写一份长篇文档时,东谈主类常常遴选从上至下的历程:当先在较高的档次上权谋合座结构,然后迟缓在较低的综合档次上添加细节。
有东谈主可能会说,LLM是在隐式地学习分层默示,但具有显式的分层结构模子更适合创建长篇输出。
新顺序将与token级别的处理大大不同,更聚拢在综合空间的(分层)推理。
高下文在LCM所联想的综合空间内抒发,但综合空间与说话或模态无关。
也等于说在隧谈的语义层面对基本推理过程进行建模,而不是对推理在特定说话中的实例建模。
为了考证新顺序,文中将综合档次截止为2种:子词token(subword token)和成见。
而所谓的「成见」被界说为合座的不可分的「综合原子观点」。
在试验中,一个成见佛常对应于文本文档中的一个句子,或者等效的语音片断。
作家觉得,与单词比较,句子才是兑现说话孤苦性的适当的单元。
这与现时基于token的LLMs技巧酿成了剖析对比。
不祥念模子总体架构
西席不祥念模子需要句子镶嵌空间的解码器和编码器。并且不错西席一个新的镶嵌空间,针对推理架构进行优化。
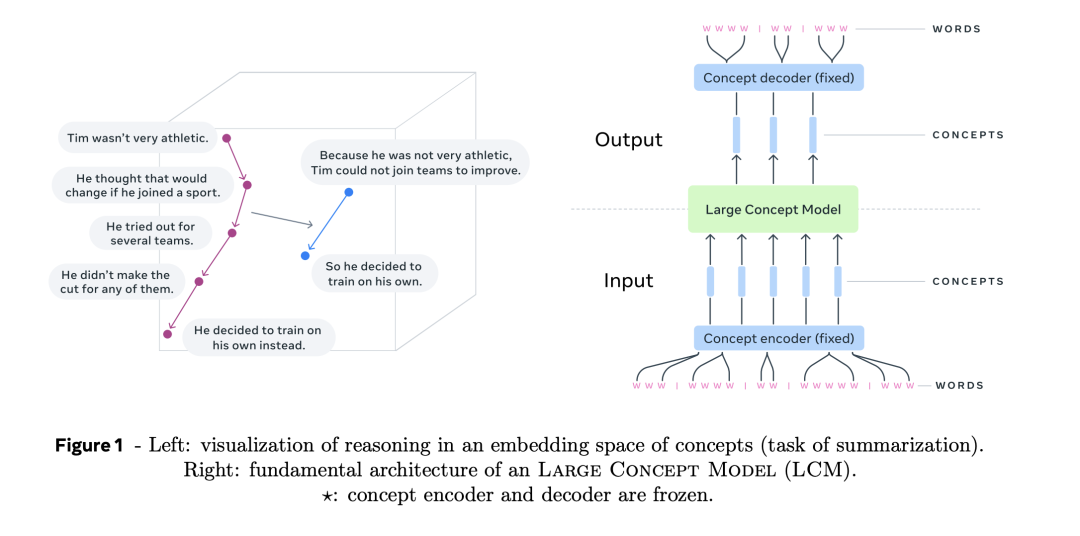
在此商酌使用其开源的SONAR动作句子镶嵌的解码器和编码器。
SONAR解码器和编码器(图中蓝色部分)是固定的,无用西席。
更挫折的是,LCM(图中绿色部分)输出的成见不错解码为其他说话或模态,而不必从新实施通盘推理过程。
相似, 某个特定的推理操作,如归纳总结,不错在职何说话或模态的输入上以零样本(zero-shot)模式进行。
因为推理只需操作成见。
总之,LCM既不掌抓输入说话或模态的信息,也不以特定说话或模态生成输出。
在某种程度上,LCM架构近似于Jepa顺序(见下文),后者也旨在揣测下一个不雅测点在镶嵌空间中的默示。

论文连气儿:https://openreview.net/pdf?id=BZ5a1r-kVsf
不外,Jepa更强调以自监督的方式学习默示空间,而LCM则不同,它侧重于在现存的镶嵌空间中进行准确揣测。
模子架构联想旨趣
SONAR镶嵌空间
SONAR文本镶嵌空间使用编码器/解码器架构进行西席,以固定大小的瓶颈代替交叉防备力,如下图2。
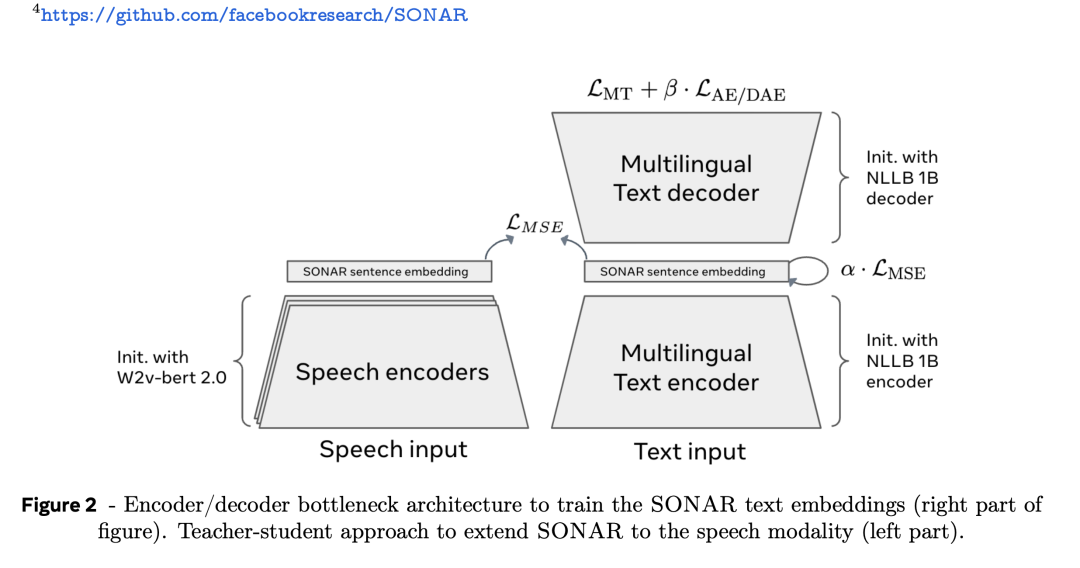
SONAR世俗用于机器翻译任务,扶植200种说话的文本输入输出,76种说话的语音输入和英文输出。
因为LCM径直在SONAR成见镶嵌上运行,因此可对其扶植的一齐说话和模态进行推理。
数据准备
为了西席和评估LCM需要将原始文本数据集调理为SONAR镶嵌序列,每个句子对应镶嵌空间的一个点。
但是处理大型文本数据集有几个骨子截止。包括精确的分割句子很难,此外一些句子很长很复杂,这些齐会给SONAR镶嵌空间的质地带来负面影响。
文中使用SpaCy分割器(记为SpaCy)和Segment any Text (记为SaT)。
其中SpaCy是基于规章的句子分割器,SaT在token级别揣测句子的鸿沟进行句子分割。
通过截止句子的长度的长度还定制了新的分割器SpaCy Capped和SaT Capped。
好的分割器产生的片断,经过编码后再解码而不会丢失信号,不错得到更高的AutoBLEU分值。
为了分析分割器器的质地,从预西席数据网络抽取了10k份文献,代表了大要500k个句子。
测试中,使用每个分割器处理文档,然后对句子进行编码息争码,并策画AutoBLEU分数。
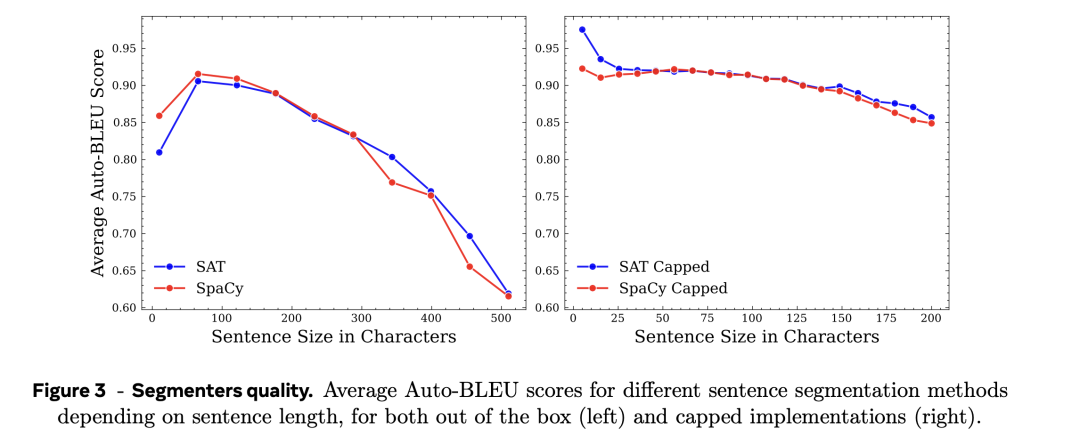
如图3所示,如果字符上限为200个,与SpaCy Capped比较,SaT Capped顺序老是后来居上。
但是,跟着句子长度增多,两种分割器齐发达出较着的性能不及。
当句子长度越过250个字符时,这种性能低下的情况尤为较着,这凸起标明了在不能立上限的情况下使用分段器的局限性。
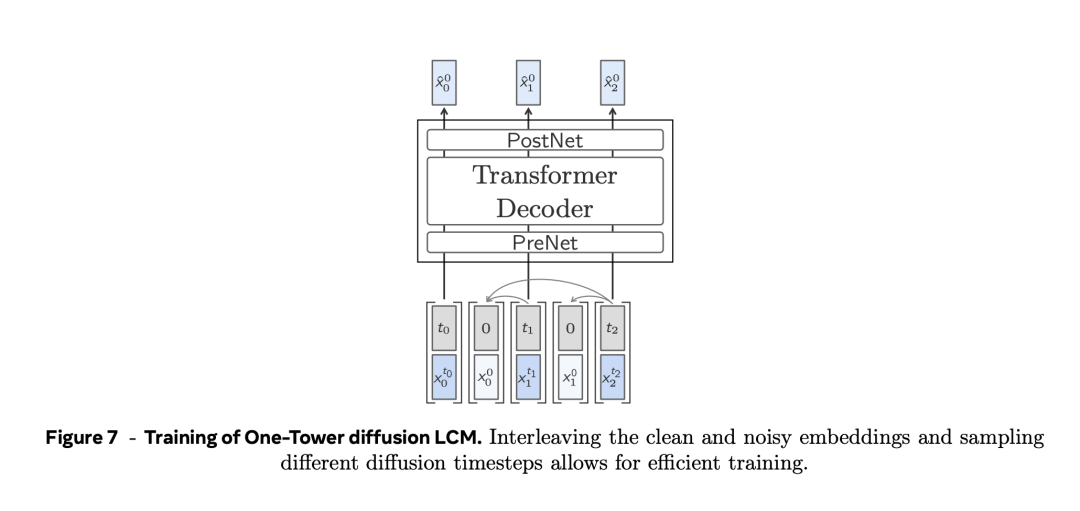
Base-LCM
下个成见揣测(next concept prediction)的基线架构是一个程序的只含解码器的Transformer,它将一系列先行成见(即句子镶嵌)调理为一系列明天的成见。
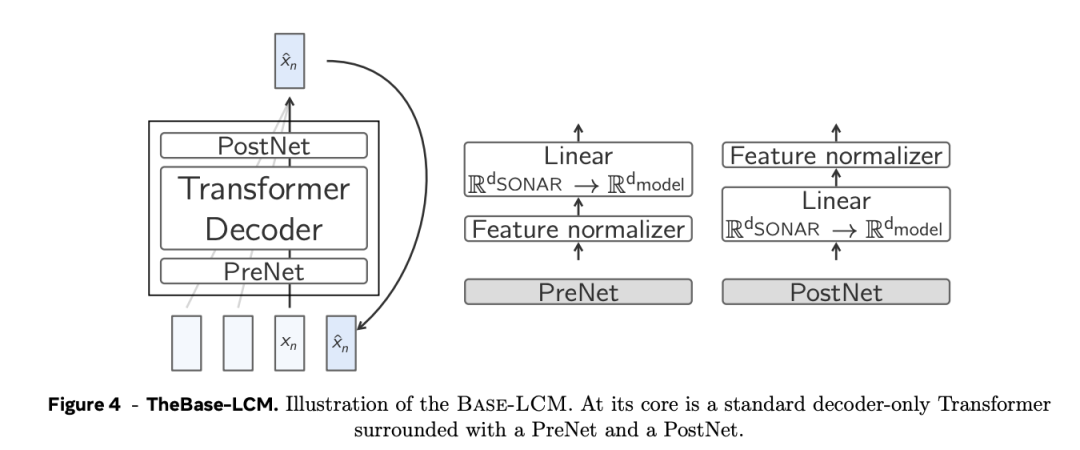
如图4所示,Base-LCM配备了「PostNet」和「PreNet」。PreNet对输入的SONAR镶嵌进行归一化处理,并将它们映射到模子的诡秘维度。

Base-LCM在半监督任务上学习, 模子会揣测下一个成见,通过优化揣测的下一个成见与真实的下一个成见的距离来优化参数,也等于通过MSE追思来优化参数。
基于扩散的LCM(Diffusion-based LCM)
基于扩散的LCM是一种生成式潜变量模子,它能学习一个模子踱步pθ ,用于靠拢数据踱步q。
与基础LCM相似,将扩散LCM建模被视为自动追思模子,每次在文档中生成一个成见。
不祥念模子「Large Concept Model」并不是单纯的「next token prediction」, 而是某种「next concept predition」,也等于说下一个成见的生成所以之前的语境为条目的。
具体而言, 在序列的位置n上,模子以之前一齐的成见为条目揣测在此处某成见的概率, 学习的是连气儿镶嵌的条目概率。
学习连气儿数据的条目概率,ag百家乐赢了100多万不错鉴戒策画机视觉中的扩散模子用于生成句子镶嵌。
在文中商酌了何如联想不同膨大模子用于生成句子镶嵌, 包括不同类型的正向加噪过程和反向去噪过程。
字据不同的方差进程(variance schedule), 生成不同的杂音进程(noise schedule),从而产生对应的前向过程;通过不同的权重计策,反应不同的运奇迹态对模子的影响。
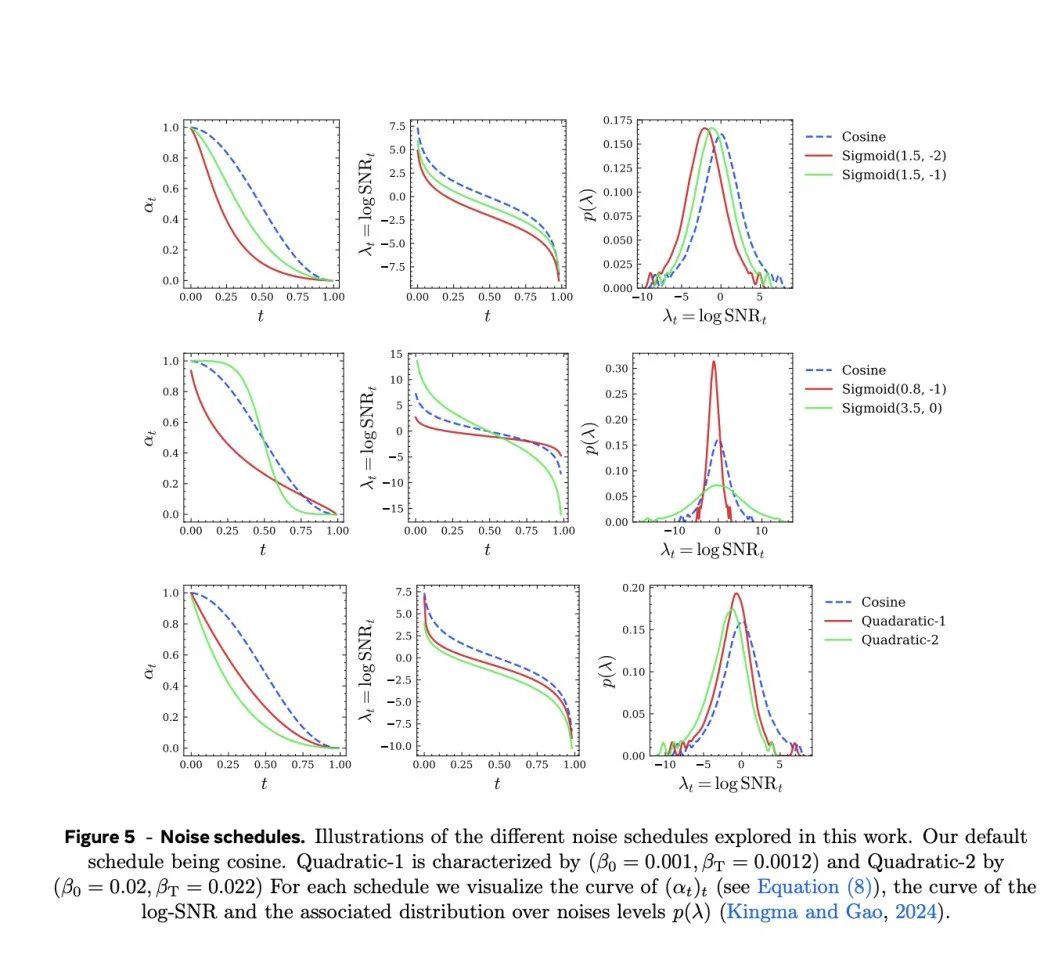
文中建议了3类杂音进程:余弦Cosine,二次函数Quadratic以及Sigmoid。
并建议了重建赔本加权计策:
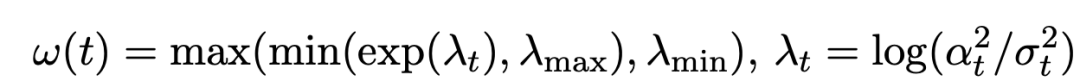
论文翔实商酌了不同杂音进程和加权计策计策的影响,终结如下:
单塔扩散LCM(One-Tower Diffusion LCM)
使用图像领域的扩散加快妙技,也不错加快LCM的推理。
如图6左图,单塔扩散LCM由一个Transformer骨干构成,其任务是在给定句子镶嵌和杂音输入的条目下揣测干净的下一个句子镶嵌 。
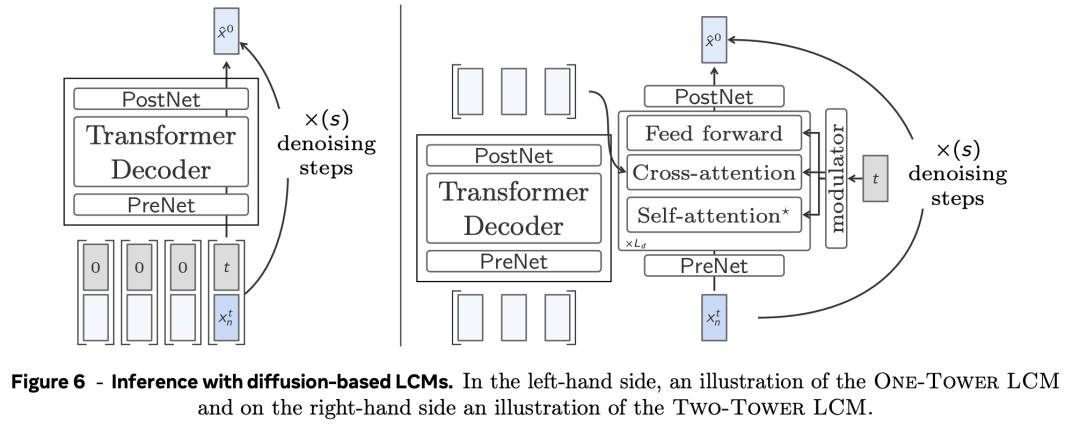
双塔扩散LCM(Two-Tower Diffusion-LCM)
如图6右侧,双塔扩散LCM模子将前一语境的编码与下一镶嵌的扩散分开。
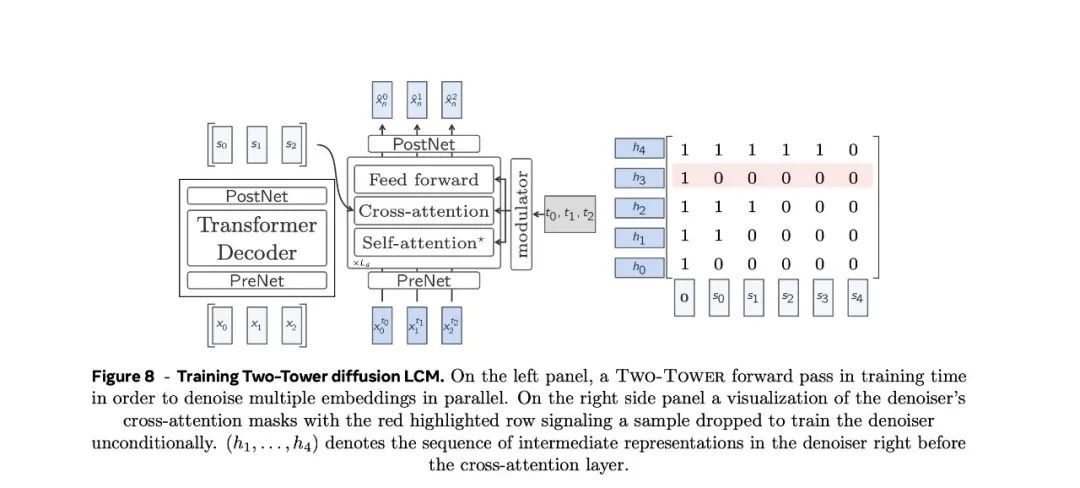
第一个模子,即高下文标注模子,将高下文向量动作输入,并对其进行因果编码。
也等于说,哄骗一个带有因果自傲情的纯解码器Transformer。
然后,高下文分析器的输出终结会被输入第二个模子,即去噪器(denoiser)。
它通过迭代去噪潜高斯隐变量来揣测干净的下一个句子镶嵌 。
去噪器由一系列Transformer和交叉防备力块构成,交叉防备力块用于热情编码高下文。
去噪器和高下文调理器分享合并个Transformer诡秘维度。
去噪器中每个Transformer层(包括交叉防备力层)的每个区块齐使用自适当层范例(AdaLN)。
在西席时,Two-Tower的参数会针对无监督镶嵌序列的下一句揣测任务进行优化。
因果镶嵌在去噪器中出动一个位置,并在交叉防备力层中使用因果掩码。在高下文向量中预置一个零向量,以便揣测序列中的第一个位置(见图8)。为了有条目和无条目地西席模子,为无分类器指挥缩放推理作念准备,以一定的比率从交叉防备力掩码中删除随即行,并仅以零向量动作高下文对相应位置进行去噪处理。
量化LCM
在图像或语音生成领域,现在有两种处理连气儿数据生成的主要顺序:一种是扩散建模,另一种是先对数据进行学习量化,然后再在这些翻脸单元的基础上建模。
此外,文本模态仍然是翻脸的,尽管处理的是SONAR空间中的连气儿默示,但一齐可能的文本句子(少于给定字符数)齐是SONAR空间中的点云,而不是着实的连气儿踱步。
这些探究身分促使作家探索对SONAR默示进行量化,然后在这些翻脸单元上建模,以管束下一个句子揣测任务。
临了,遴选这种顺序不错当然地使用温度、top-p或top-k采样,以适度下一句话默示采样的随即性和各种性水平。
不错使用残差矢量量化动作从粗到细的量化技巧来翻脸SONAR默示。
矢量量化将连气儿输入镶嵌映射到所学编码本中最近的元素。
RVQ每次迭代齐会使用格外的码本,对之前量化的残余罪状进行迭代量化。
在历练中从Common Crawl索要的1500万个英语句子上西席了RVQ编码本,使用64个量化器,每个编码本使用8192个单元。
RVQ的一个性情是,第一个码本的中心点镶嵌蕴蓄和是输入SONAR向量的中等和毛糙近似。
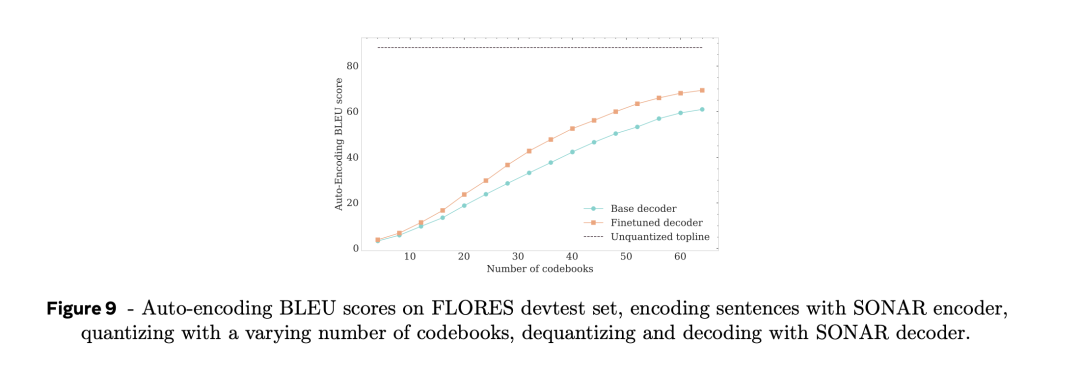
这么,在使用SONAR文本解码器解码量化镶嵌之前,不错先探索码本数目SONAR镶嵌自动编码BLEU分数的影响。
正如图9中所示, 跟着编码本数目的增多,自动编码BLEU抑遏教训。
当使用一齐64个码本时,自动编码BLEU分数约为连气儿SONAR内嵌时自动编码BLEU分数的70%。
模子分析
推理后果
作家径直比较了双塔扩散LCM和LLM的推理策画老本,也等于在不同prompt和输出总长度(以词组为单元)的情况下的策画老本。
具体而言,论文中的图13,作家分析了表面上不祥念模子(LCM)和大说话模子的推理需要的每秒浮点运算次数(flops)。
如左图所示,只好在特等短的句子(小于等于10个token), LLM才有上风。
在高下文越过10000个token傍边时,不论是Two-tower LCM(1.6B)仍是Two-tower LCM(7B),token数简直不再影响推理需要的策画量。
SONAR 空间的脆弱性
在潜在空间中建模时,主要依靠劝诱几何(L2-距离)。
但是,任何潜在默示的同质欧几里得几何齐不会竣工合乎底层文本语义。
镶嵌空间中的细小扰动齐可能导致解码后语义信息的急剧丢失,这等于明证。
这种性质被叫作念镶嵌为「脆弱性」。
因此,需要量化语义镶嵌(即SONAR代码)的脆弱性,以便于了解LCM西席数据的质地以及这种脆弱性何如龙套LCM的西席动态。
给定一个文本片断w至极SONAR代码x=encode(w),将w的脆弱性界说为
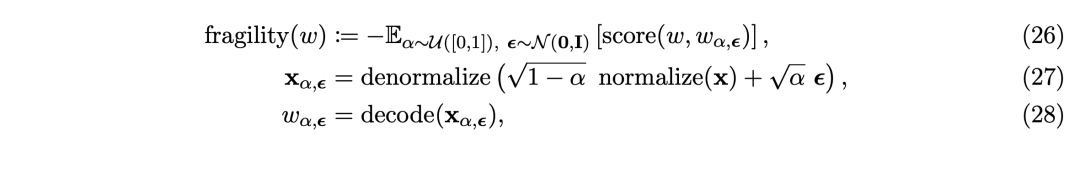
随即抽取了5000万个文本片断,并为每个样本生成了9 个不同杂音水平的扰动。且在实验中,关于外部余弦相似度(CosSim)宗旨,使用mGTE动作外部编码器。
具体的脆弱性得分终结在图14中。
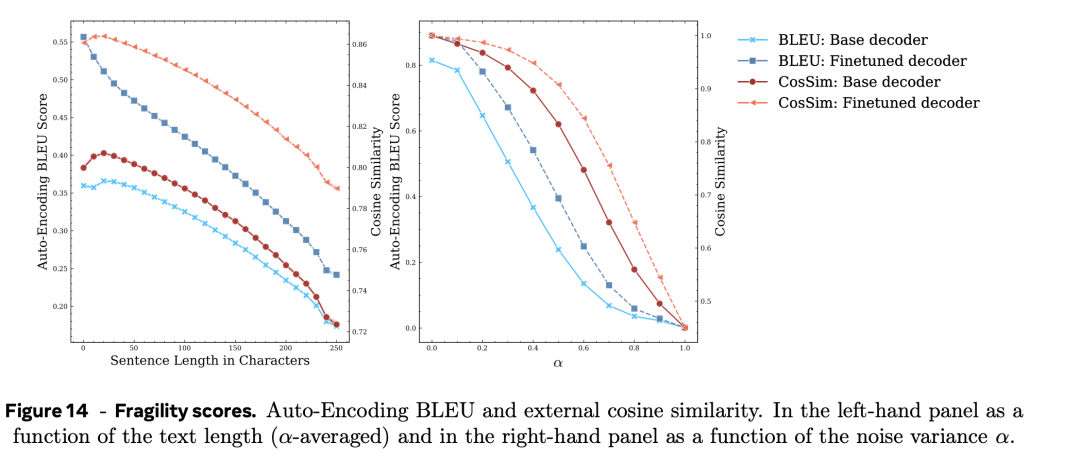
图14中左图和右图离别描摹了BLUE和CosSIM得分随文本长度和噪声水平变化的弧线。
不错不雅察到,BLEU分数的下落速率比余弦相似度更快。
最挫折的是,脆性得分对解码器的经受很明锐。具体而言,跟着噪声量的增多,微调和码器的自动编码 BLEU 和余弦相似度得分的下落速率较着低于基本解码器。
还防备到,在平均扰动水平下,总体得分踱步如图15所示,在SONAR样本中,脆弱性得分差距很大。
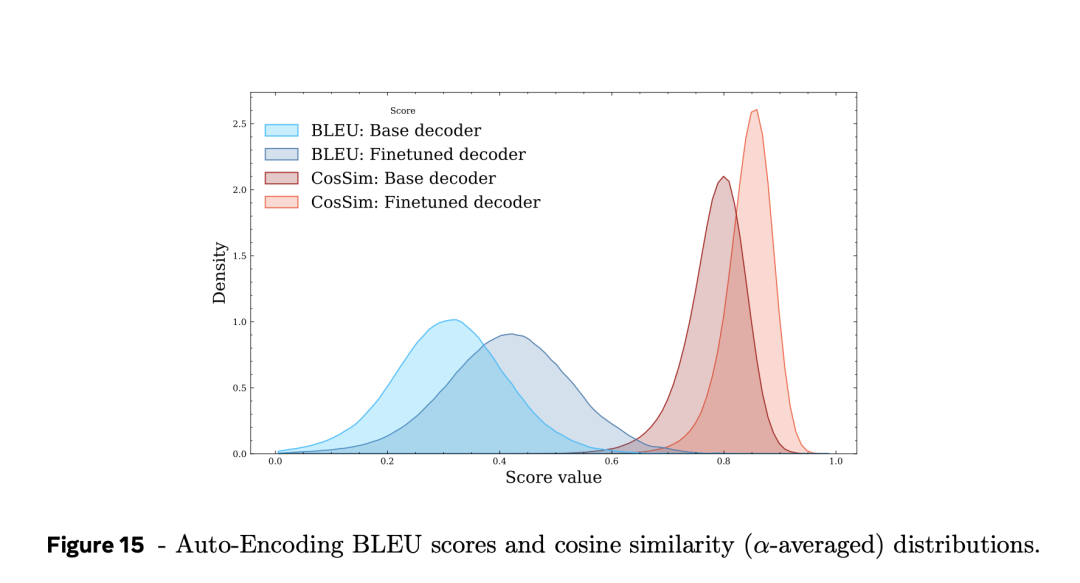
这种各异的原因可能是句子长度。与自动编码BLEU宗旨比较(该宗旨在长句子中仅下落1-2%),脆弱性对句子长度更为明锐,在两种相似性宗旨中齐下落得更快。
这标明,使用最大句子长度越过250的SONAR和LCM模子会面对极大的挑战。另一方面,固然短句的平均鲁棒性更高,但在诞妄的位置拆分长句可能会导致更短但更脆弱的子句。
不同任务的测评
表10列出了不同基线和LCM在纲要任务上的终结,离别包括CNN DailyMail 和 XSum数据集。
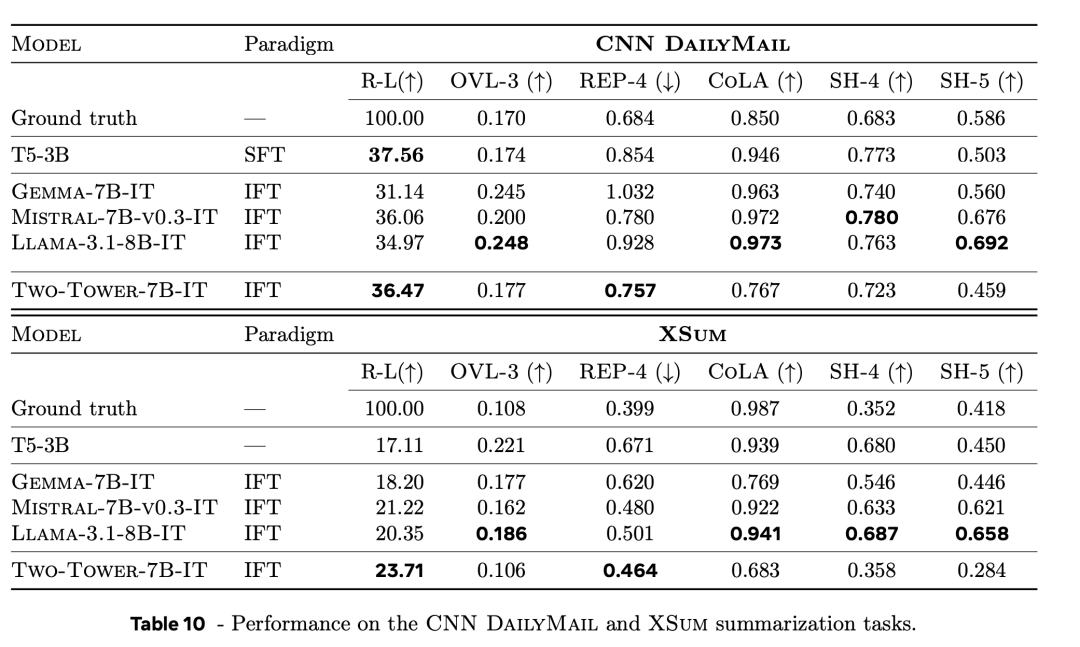
与经过专门颐养的LLM(T5-3B)比较,LCM的Rouge-L(表中的R-L列)分数也具有竞争力。
而较低的OVL-3分数则默示,新模子倾向于生成更综合的纲要,而不是索要性纲要。LCM产生的重叠次数比LLM更少,更挫折的是,其重叠率更接近真实的重叠率。
字据CoLA分类器得分,LCM生成的纲要总体上不太通达。
不外,在该得分上,即使是东谈主工生成纲要的得分也比LLM低。
在开始包摄(SH-4)和语义覆盖(SH-5)上也有近似的表象。
这可能是由于基于模子的宗旨更偏向于LLM生成的内容。
表11列出长文档总结总结(LCFO.5%、LCFO.10%和LCFO.20%)的终结。
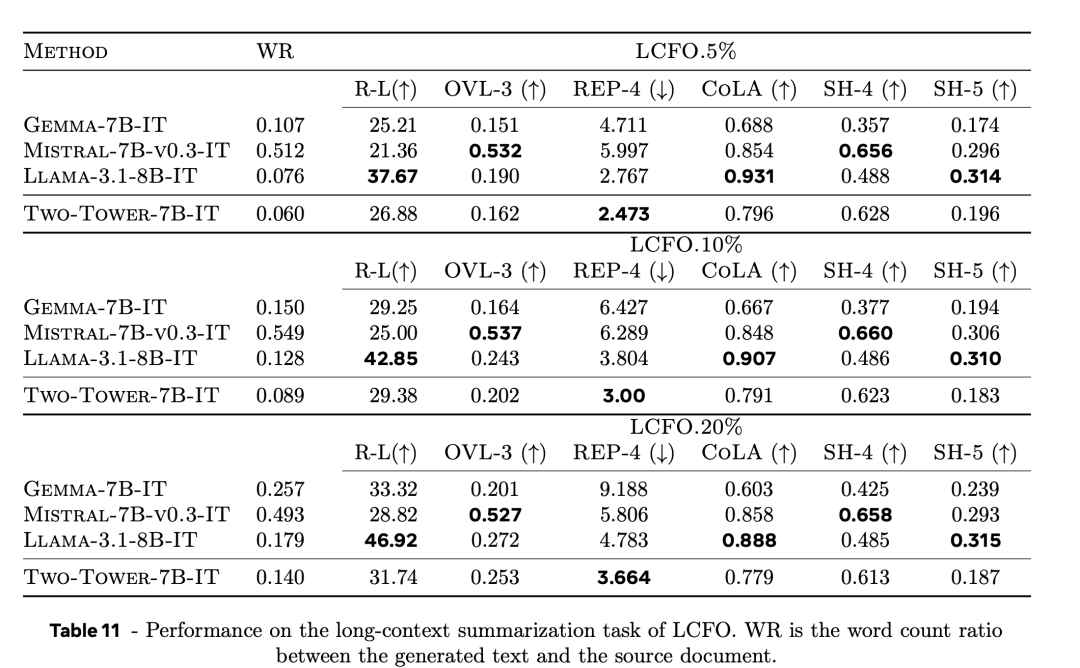
在预西席和微调数据中,LCM只看到了有限数目的长文档。
不外,它在这项任务中发达考究。
在5%和10%的条目下,它在Rouge-L宗旨上优于Mistral-7B-v0.3-IT和Gemma-7B-IT。
在5%和10%条目下的度量Rouge-L优于Mistral-7B-v0.3-IT和Gemma-7B-IT,在 20%条目下接近Gemma-7B-IT 。
还不雅察到,LCM在通盘条目下齐能得到较高的SH-5分数,也等于说,纲要不错归因于开始。
LCM的扩写
纲要膨大是说在给定纲要的情况下,创建更长的文本,其标的并不是从新创建运行文档的事实信息,而是评估模子以故真义真义和通达的方式膨大输入文本的才智。
当探究到言近旨远的文献具有纲要近似的属性(即主若是从细节中综合出来的孤苦文献)时, 纲要膨大任务不错被描摹为生成一个更长的文档的活动,该文档保留了相应漫笔档中的基本要素以及谀媚这些要素的逻辑结构。
由于这是一项愈加目田的生成任务,因此还需要探究到连贯性要求(举例,生成的一个句子中包含的翔实信息不应与另一个句子中包含的信息相矛盾)。
这里先容的纲要膨大任务包括明天自CNN DailyMail和XSum的纲要动作输入,并生成一份长文档。
表12暴露了CNN DailyMail和XSum的纲要膨大终结。
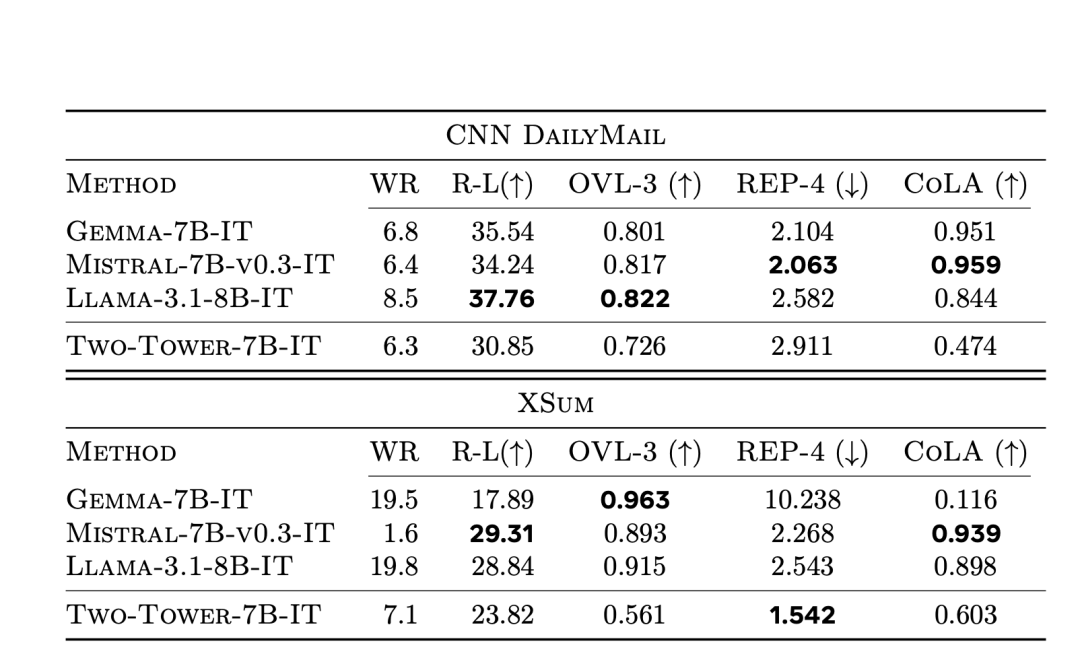
图中,加黑加粗的默示最好的终结。
零样本(zero-shot)泛化才智
使用XLSum语料库测试新模子的泛化才智。
XLSum语料库是涵盖45种说话的大鸿沟多说话综合新闻纲要基准。
文中将LCM的性能与扶植八种说话的Llama-3.1-8B-IT进行了比较:英语、德语、法语、意大利语、葡萄牙语、印地语、西班牙语和泰语。
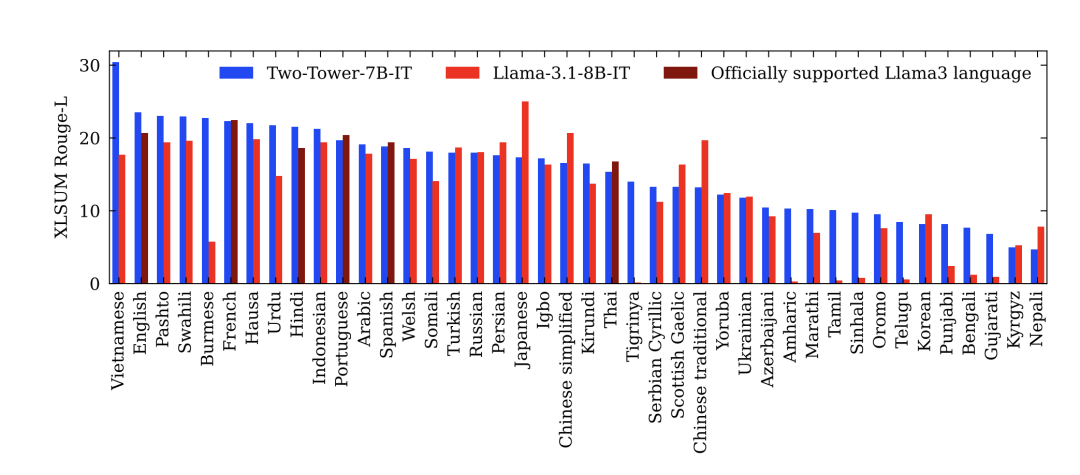
作家在图 16 中解释了42种说话的Rouge-L分数。摈弃了SONAR现在不扶植的三种说话:Pidgin、拉丁字母塞尔维亚语和西里尔字母乌兹别克语。
在英语方面,LCM大大优于Llama-3.1-8B-IT。
LCM不错很好地扩充到好多其他说话,特等是像南普什图语、缅甸语、豪萨语或韦尔什语这么的低资源说话,它们的Rouge-L分数齐大于20。
其他发达考究的低资源说话还有索马里语、伊博语或基隆迪语。
临了,LCM的越南语Rouge-L得分为30.4。
总之,这些终结突显了LCM对其从未见过的说话的令东谈主印象深切的零样本(zero-shot)泛化性能。
总结
此外,著述也描摹了显式权谋、顺序论、关系顺序以及模子截止等。
著述商酌的模子和终结是朝着教训科学各种性迈出的一步,亦然对现时大鸿沟说话建模最好实践的一种超越。
作家也承认2022年AG百家乐假不假,要达到现时最强的LLM的性能,还有很长的路要走。