网络彩票和AG百家乐
AI海浪之下,互联网大厂“内卷”的赛谈尤为贯通,一致将主义锁定大模子。从百度的文心一言到阿里的通义千问,从腾讯混元到字节豆包……各厂均卷出了自家的大模子。而在全球豪恣磨砺大模子的背后,数据这一“硬通货”尤为伏击。
毕竟,数据是大模子的“食粮”。数据的质料和数目将径直影响着大模子的性能和准确度。跟着大模子赛谈的加快“内卷”,未来关于数据的需求量只会越来越多,质料条目也会越来越高。
数据将是未来AI大模子竞争的关键因素
东谈主工智能发展的唐突获利于高质料数据的发展。举例,大型言语模子的最新发达依赖于更高质料、更丰富的磨砺数据集:与GPT-2比拟,GPT-3对模子架构只进行了渺小的修改,但破耗元气心灵网罗更大的高质料数据集进行磨砺。ChatGPT与GPT-3的模子架构访佛,并使用RLHF(来自东谈主工响应过程的强化学习)来生成用于微调的高质料记号数据。

东谈主工智能领域以数据为中心的AI,即在模子相对固定的前提下,通过擢升数据的质料和数目来擢升统共这个词模子的磨砺遵守。擢升数据集质料的时势主要有:添加数据记号、清洗和治疗数据、数据缩减、增多数据千般性、捏续监测和保养数据等。未来数据老本在大模子开荒中的老本占比或将擢升,主要包括数据采集,清洗,网络彩票和AG百家乐标注等老本。
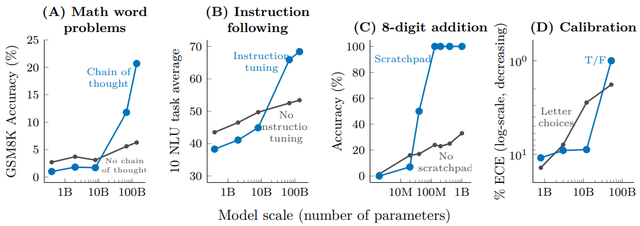
以数据为中心的 AI:模子不变,通过改换数据集质料擢升模子遵守
AI大模子需要什么样的数据集
1)高质料:高质料数据集不祥提高模子精度与可暴露性,况兼减少经管到最优解的工夫,即减少磨砺时长。
2)大边界:OpenAI 在《Scaling Laws for Neural Language Models》中提倡 LLM 模子所投诚的“伸缩规则”(scaling law),即落寞增多磨砺数据量、模子参数边界或者延迟模子磨砺工夫,预磨砺模子的遵守会越来越好。
3)丰富性:数据丰富性不祥提高模子泛化才气,过于单一的数据会极度容易让模子过于拟合磨砺数据。
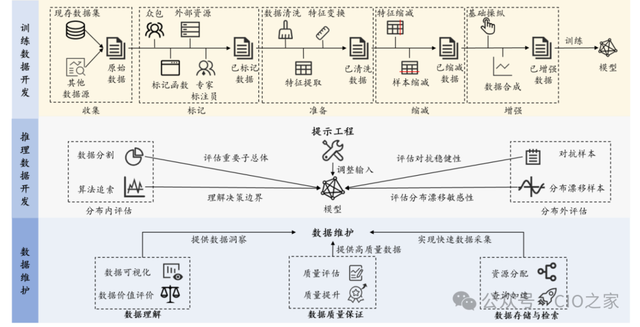
数据集奈何产生
开荒数据集的历程主要分为 1)数据采集;2)数据清洗:由于采集到的数据可能存在缺失值、噪声数据、叠加数据等质料问题;3)数据标注:最伏击的一个尺度;4)模子磨砺:模子磨砺东谈主员会诈欺标注好的数据磨砺出需要的算法模子;5)模子测试:审核员进行模子测试并将测试肆意响应给模子磨砺东谈主员,而模子磨砺东谈主员通过阻挡地调整参数,以便赢得性能更好的算法模子;6)家具评估:家具评估东谈主员使用并进行上线前的临了评估。
数据采集:采集的对象包括视频、图片、音频和文本等多种类型和多种体式的数据。数据采集现在常用的有三种样式,分别为:1)系统日记采集时势;2)集会数据采集时势;3)ETL。

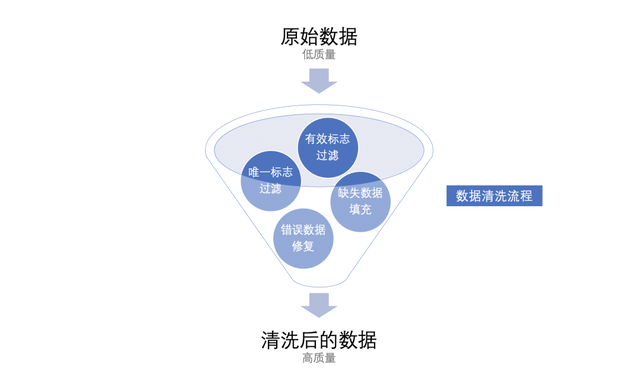
数据清洗:数据清洗是提高数据质料的有用时势。由于采集到的数据可能存在缺失值、噪声数据、叠加数据等质料问题,故需要实施数据清洗任务,数据清洗动作数据预处理中至关伏击的尺度,清洗后数据的质料很猛进度上决定了 AI 算法的有用性。
数据标注:数据标注是历程中最伏击的一个尺度。惩办员会把柄不同的标注需求,将待标注的数据分手为不同的标注任务。每一个标注任务王人有不同的设施和标注点条目,一个标注任务将会分派给多个标注员完成。
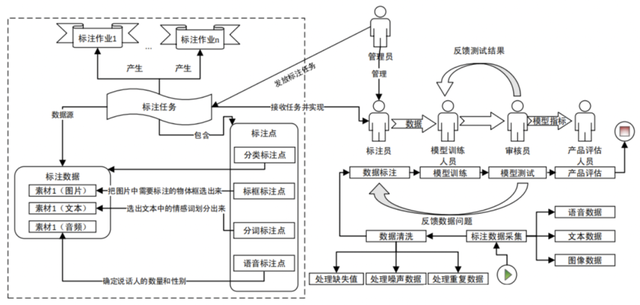
模子磨砺与测试:最终通过家具评估尺度的数据才算是确实过关。家具评估东谈主员需要反复考据模子的标注遵守ag真人百家乐会假吗,并对模子是否昂然上线主义进行评估。