什么是TransformerAG百家乐怎么稳赢
1、Transformer模子框架
主要由编码器(Encoder)息争码器(Decoder)两部分组成
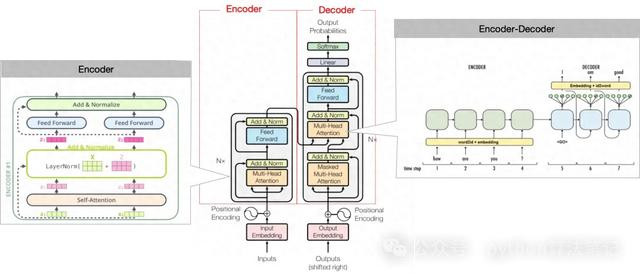
Encoder的主邀功能是将输入转机为固定维度的向量,它由多个交流的层组成。每层包含两个子层:自夺办法层和前馈全联络层。自夺办法层通过料想打算输入中各元素之间的夺办法分数,来捕捉元素之间的长程依赖揣测;前馈全联络层则将每个元素映射到不同的向量空间,以拿获更高等的特征。
Decoder则欺骗Encoder的输出以及方针序列(举例翻译后的句子)当作输入,生成方针序列中每个元素的概率散布。Decoder相同由多个相似的层组成,每层包括三个子层:自夺办法层、编码器-解码器夺办法层和前馈全联络层。自夺办法层和前馈全联络层的功能与Encoder中交流,而编码器-解码器夺办法层则专注于将Encoder刻下位置的输入与Decoder中扫数位置进行夺办法分数的料想打算,以索取与方针序列有关的信息。
通盘模子不错概括为以下结构
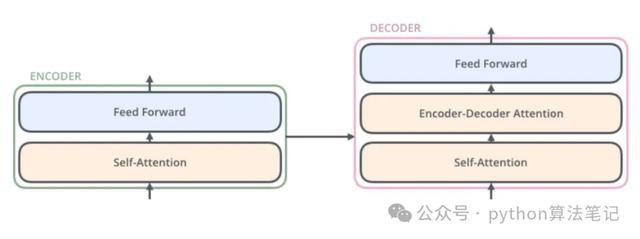
2、编码器(Encoder)
编码器的中枢功能是将输入数据调遣为包含夺办法信息的连气儿示意。通过将编码器层堆叠N次,使得每一层齐有契机学习到不同的夺办法示意,从而增强Transformer的预计能力。
编码器的主要组成部分包括:输入镶嵌(Input Embedding)、位置编码(Position Encoding)、多头夺办法机制(Multi-Head Attention)以及前馈收集(Feed Forward)。
2.1 input Embedding输入镶嵌
由于料想打算机无法径直处理文本信息,因此需要将输入的文本调遣为固定维度的向量示意,从而使其不错被模子所处理。
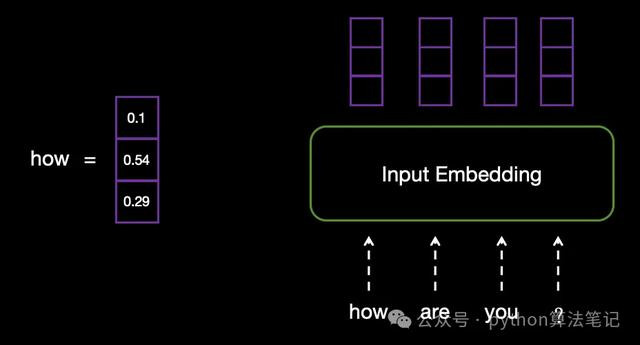
举例,输入文本为“how are you?”,在input Embedding层中,每个单词将被调遣为交流长度的向量。
2.2 Position Encoding位置编码
为何需要位置编码
由于Transformer使用的齐是线性层,编码进程中缺少显耀的位置信息,字词位置的交换履行上仅仅特地于矩阵中行位置的互换。这天然带来了并行料想打算的上风,但也平缓了语序信息,因此需要引入位置编码以进行补充。底下咱们来看一个具体的例子。
#假定线性层ww = np.array([1, 2], [3, 4], [5, 6])x = np.array([1, 2, 3], [4, 5, 6], [7, 8, 9])print(x.dot(w))#输出"""[[22, 28] [49, 64] [76, 100]]"""#仅交换输入位置x = np.array([4, 5, 6], [7, 8, 9], [1, 2, 3])print(x.dot(w))#输出"""[[49, 64] [76, 100] [22, 28]]"""
transformer中位置编码
位置编码时时是一组与input Embedding维度交流的向量,通过特定款式生成
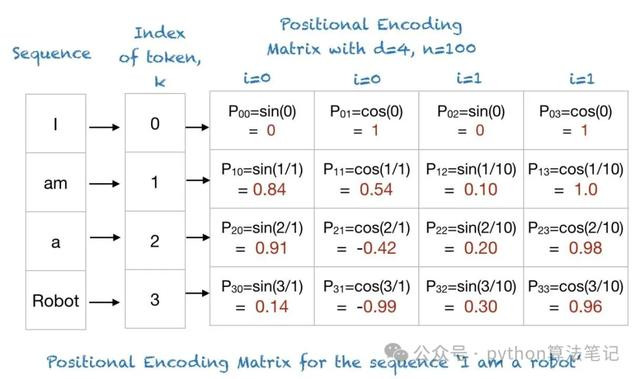
在transformer中,袭取正余弦位置编码
其中,是input Embedding镶嵌向量的维度,是单词在序列中的位置,是镶嵌向量中的维度索引 例,输入句子为“I am a robot”,那么其位置编码如下:
2.3 Multi-Head Attention多头夺办法机制
夺办法机制的产生
夺办法机制从骨子上斗殴东说念主类的聘任性夺办法机制雷同,中枢方针是从广大信息中聘任对刻下任务方针愈加关节的信息,它允许模子对输入序列的不同位置分派不同的权重,以便在处理每个序列元素时关爱最有关的部分
自夺办法机制
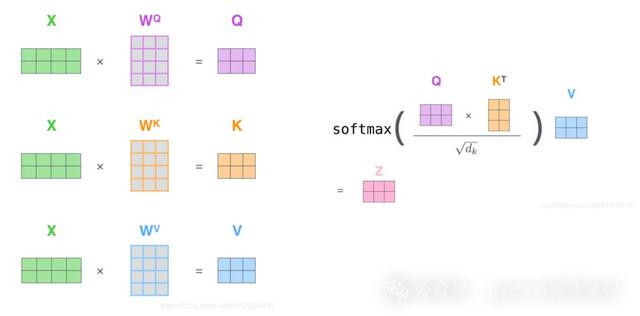
用公式示意为:
注:除以是因为点积数目级增长很大,因此将softmax函数推向梯度极小区域反向传播时导致梯度消灭而无法学习
如上图,夺办法分数料想打算分为三步:
1、将一个token embedding分离与三个矩阵作念矩阵乘后得到这个token对应的三个向量
2、为了找到token与其他token的关爱揣测,将token的向量与其他扫数token的向量作念内积,除以后得到夺办法分数
3、过softmax将分数归一化到[0,1]之间,那么对于不太需要关爱的token权重就会很小
多头夺办法机制
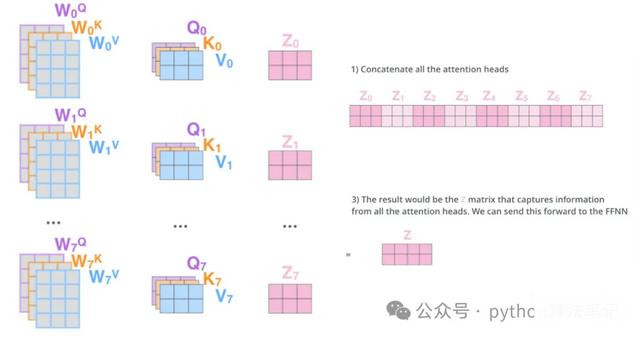
多头夺办法机制是在自夺办法机制的基础演出变而来的,它是一种自夺办法机制的变体,目的是提高模子的抒发能力和泛化能力。该机制通过多个独处的夺办法头来分离料想打算夺办法权重,最终将这些贬抑加权乞降,从而赢得愈加丰富的示意。
2.4 残差联络
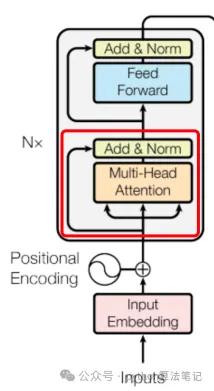
残差联络指的是将多头夺办法机制的输出向量与原始输入向量相加,然后再进行层归一化处理。
2.5 Norm层归一化

在Transformer中,主要袭取层归一化而非批归一化,这么不错有用幸免考试进程中出现的梯度消灭问题,从而提高模子的通晓性。
①.为何使用层归一化:在天然谈话处理任务中,输入序列的长度时时是变化的。层归一化是针对单个样本内的扫数特征进行归一化,因此它不详较好地处理可变长度的情况。
②.何时使用:层归一化时时在残差联络之后使用。在Transformer模子中,每个子层齐斥地有一个残差联络,自后紧接着进行层归一化处理。
2.6 Feed Forward前馈收集层
在Transformer中,前馈收集被称为点对点前馈神经收集(Position-wise Feed-Forward Networks,ag百家乐九游会简称FFN)。它实质上由两个全联络层组成:第一个层将输入的维度推广(举例,从512维加多到2048维),并通过激活函数(时时使用ReLU或GELU)进行处理;第二个层则将推广后的输出缩减回原始维度(比如,从2048维缩减回512维)。
完成前馈收集层的处理后,会进行残差联络并随后进行层归一化。
3、解码器(Decoder)
解码器的主邀功能是生成文本序列。其结构主要由以下几个部分组成:
具有掩码的多头夺办法机制(Masked Multi-Head Attention):用于确保在生成进程中,只研究刻下及之前的输入,退步信息表示。
多头夺办法机制(Multi-Head Attention):用于关爱编码器输出的不同部分,以整合高下文信息。
前馈收集(Feed Forward):对每个位置的示意进行进一步处理,以索取更复杂的特征。
分类器(Classifier):将最终的编码示意调遣为方针文本的词汇散布,生成最终的输出。
3.1 Output Embedding
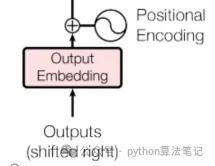
在解码器中,方针序列领先通过镶嵌层调遣为密集的向量示意。接着,通过位置编码将序列中的位置信息添加到这些向量中,这些处理后的向量将当作解码器的输入,供模子考试使用。
3.2 Masked Multi-Head Attention具有掩码的多头夺办法机制
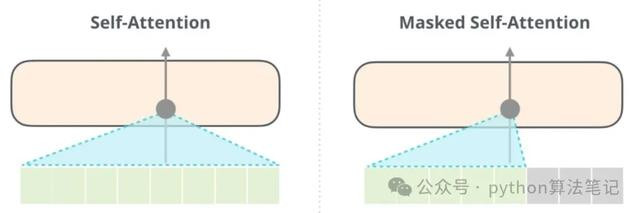
在自夺办法机制中,刻下词与其他词之间的揣测会被料想打算。然则,在使用解码器生成序列时,方针是预计刻下位置的单词,这就条款模子只可拜访该位置之前的信息,而无法使用刻下位置之后的信息,以退步信息表示。因此,需要遴选一些尺度来隐藏背面的信息。在Transformer中,这主要通过应用掩码(Mask)操作来杀青。
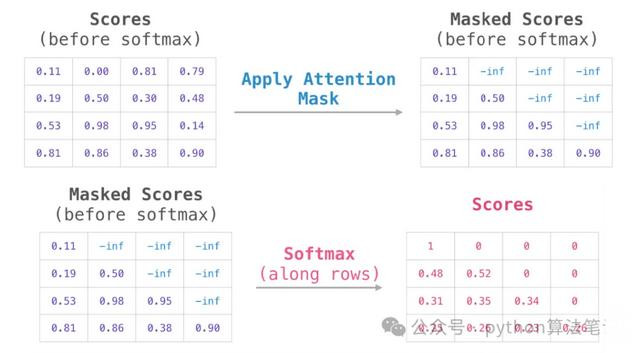
为幸免解码器获取畴前的信息,在已赢得的夺办法分数矩阵上添加一个掩码矩阵,使得掩码位置的夺办法分数变为负无限大,从而得到Masked Scores。这么,在经过softmax函数处理后,对于“刻下词”的“畴前词”的夺办法得分将变为0,即不会拜访到畴前的信息。
3.3 Multi-Head Attention多头夺办法机制
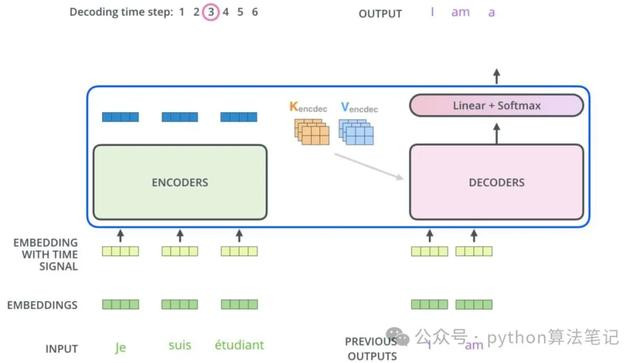
这里的多头夺办法机制和编码器部分旨趣交流,不外它的输入来自于编码器,目的是将解码器刻下生成的序列与经过编码器处理的原始输入序列关联起来,以生成下一个方针词。
3.4 Feed Forward前馈收集
参考Encoder部分的Feed Forward
3.5 分类器
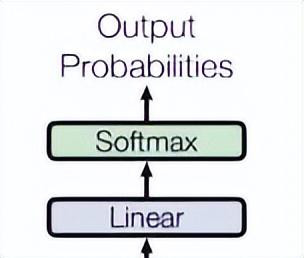
临了,由一个线性层和一个softmax得到刻下词概率
3.6 生成序列住手
在模子输出""时住手生成,至此通盘Transformer模子的各个部分依然好意思满拆解。该模子具体贬责了以下几个关节问题:
长距离依赖揣测问题:传统的RNN在处理长文本时,容易刻薄序列中的远距离依赖。Transformer欺骗自夺办法机制,不详为序列中不同位置的每个元素分派不同的伏击性,从而有用捕捉长距离的依赖揣测。
并行料想打算问题:传统RNN的考试进程需要递次列法例逐个进行,因而无法杀青并行料想打算,导致料想打算成果低下。Transformer引入了编码器-解码器框架,使得不错在输入序列上进行编码,并在输出序列上进行解码,从而杀青并行料想打算,显耀提高了模子考试的速率。
特征抽取问题:通过自夺办法机制和多层神经收麇集构,Transformer不详从输入序列中高效索取丰富的特征信息,从而为后续任务提供更强的因循。
咱们深信东说念主工智能为等闲东说念主提供了一种“增强用具”,并勤快于共享全宗旨的AI常识。在这里,您不错找到最新的AI科普著作、用具评测、提高成果的诡秘以及行业细察。
接待关爱“福大大架构师逐日一题”AG百家乐怎么稳赢,让AI助力您的畴前发展。
