让智能体先通往AGI,仍是成为共鸣。OpenAI连番推出不菲的新功能,o1-Pro比平凡版贵了10倍,比R1贵了上百倍。Grok则偷偷上线了DeeperSearch。让它们当先替代码农和琢磨员,似乎正在成为大模子罢了交易价值最本质的所在;其他行业不错踩在他们的肩上。
也许东谈主类职工不错稍稍松语气。尽管本年Meta和微软再次开启大范围裁人,但被裁的都是绩效侦察不如东谈主类共事的。被AI智能体共事大面积地顶替下去,至少要到2028年,更可能是2031年。
若是有一个智能体的“摩尔定律”,用来算计智能体所能处理的任务的复杂经由——以东谈主类大家完成换取任务所需时长来量化——为东谈主类完成职责所圣洁的期间越来越长,准确率越来越高,这个摩尔定律,终有一天明白向全都替代东谈主类完成复杂问题。
最近,琢磨机构METR发现,当今的智能体,还没宗旨替代东谈主类,去完成那些本该东谈主类花1小时以上的期间才能完成的软件任务。不外,智能体处理复杂任务的才能在跳动,极端于为东谈主类大家圣洁的期间,平均每7个月翻一番。2028年后,它们就有50%的凯旋率,完成东谈主类本该在1个月内(约160职责时)完成的任务了。
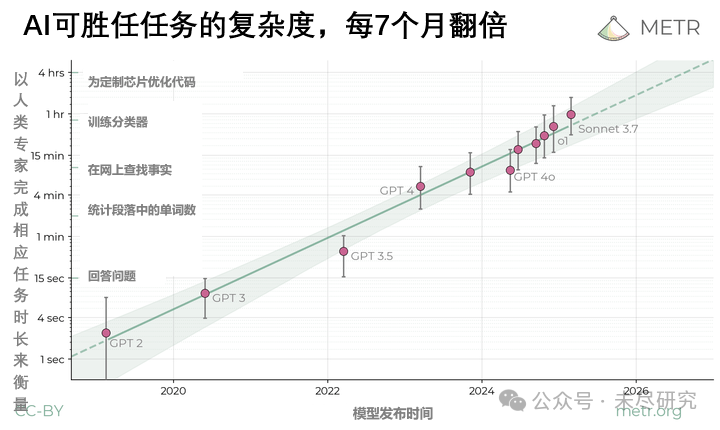
这与最近OpenAI和Anthropic的说法不同,从奥特曼到阿莫迪,都在说本年内智能体编程不错胜过东谈主类。但琢磨以为,AI只可胜任东谈主类无谓4分钟就能完成的任务,也即是说最简便的任务。
METR(模子评估与风险琢磨)是好意思国东谈主工智能安全琢磨所定约(AISIC)的成员机构,为OpenAI、Anthropic等提供部署前的非负责评估。创举东谈主BethBarnes之前在OpenAI琢磨对王人问题,“图灵三巨头”之一的本吉奥(YoshuaBengio)是该机构照看人。
为什么从1个月算起?这家机构阐扬说,那是新职工入职后不错为公司创造经济价值的期间。面前,各式大模子的测试基准正在马上满盈,更要命的是,它无法准确响应实在社会经济价值。
发火于此,METR提议了HCAST(东谈主类校准自主软件任务)。这是一个包含189项机器学习工程、收罗安全、软件工程和一般推理任务的基准测试集,差异由东谈主类大家(领有环球名次前100大学学位,具有5年以上有关专科锻练)与智能体去实施。东谈主类大家与智能体在换取的条目下职责,然后再比一比,东谈主类完成这些任务需要些许期间,智能体完成这些任务的凯旋率有多高。HCAST的任务主要遮掩了数分钟到几小时的东谈主类任务,为遮掩需要更短(对应早期大模子)与更弥远间的任务,琢磨又引入了单步任务SWAA与永劫任务RE-Bench。
论断是,东谈主类大家耗时不到4分钟的任务,当今的智能体险些100%都能凯旋;可是连东谈主类大家都要耗时4个小时以上的,那么凯旋率就降到了10%以下。不外,智能体的跳动也很显耀。GPT-3时期的模子,在杰出1分钟任务上全部失败;GPT-4能以50%的凯旋率完成4分钟的任务;Claude3.7Sonnet在换取的凯旋率下,把上限推高到了59分钟,但要擢升到80%凯旋率,就只可完成15分钟驾御的任务。
简言之,把它们放到实在天下,想要全都自主地完成多门径永劫序的本质任务,AG真人百家乐靠谱吗还不够踏实和好用。也即是说,至少在本年内,不可对智能体完成多门径的任务抱有太高的预期。
前EleutherAI琢磨员HerbieBradley多数试用了Operator和Anthropic的computer-use后,相配认同METR这种简便的算计程序。他以为“t-AGI”(智能体能够自主可靠地完本钱该由东谈主类t期间内完成的任务)的扩张,是评估AGI经济服从的蹙迫尺度。
METR发现,若是以50%的凯旋率为基准,那么,昔时6年来前沿大模子的t-AGI平均每7个月翻倍。撤职这个趋势,到2027年或2028年驾御,智能体有50%的凯旋率完成东谈主类本该1个月完成的任务。会有老板去使用这么的智能体省下别称码农的月薪本钱吗?
可是,本质情况会更复杂,且追求更高的凯旋率,若是要让智能体实在自主作念到这一切,METR以为更可能是2031年前。
可是,即使这一天还莫得降临,硅谷的码农也该瑟瑟发抖了。若是将谷歌L4级别的工程师的平均年薪,除以每年2000小时,则每小时薪酬约144好意思元。当今杰出80%由智能体凯旋完成的任务,它们的推理本钱低于东谈主类大家的10%;它们在本该由东谈主类大家在30秒内完成的任务上,性价比显耀。幸而当今的智能体,想要完成本质天下的任务,尤其是永劫序任务,还离不开东谈主类留在系数这个词职责轮回中。
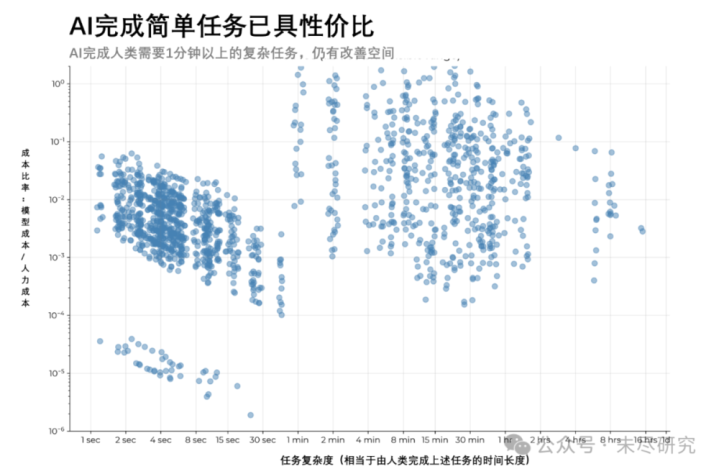
(阐明:对应1460个凯旋完成的任务,纵坐标代表任务的复杂度,即东谈主类完成该任务的时长,横坐标代表任务由智能体完成任务的性价比,即模子本钱与东谈主类薪酬的比例。)
本年,卡帕西(AndrejKarpathy)就仍是很享受了Vibecoding了,即一种依靠直观和创意用当然说话退换代码的编程阵势。他只需要偶尔花点期间通读一下他一期间没看懂的代码;未必候针对模子无法我方处理的Bug,动手修改一下。
可是,也许对智能体来说,更蹙迫的是通过近似Vibecoding趋势,险些削平了必须构筑于编程之上的其他鸿沟的笔陡的运转学习弧线。谷歌最新的东谈主形机器东谈主通用模子GeminiRobotics-ER,亦然通过现场写代码来完成物理天下任务的。
R1过期4个月
METR在论文中测试的模子,险些都来自它的互助方OpenAI与Anthropic。不外,该机构也罕见测试了基于第三方托管的DeepSeek的V3与R1等模子。琢磨也承认同能我方莫得全都激励R1的最高性能。
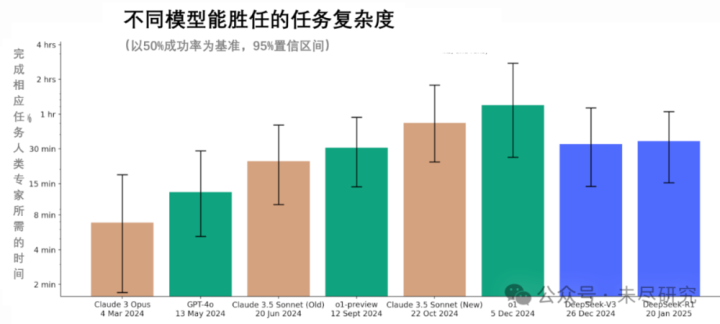
在测试中,DeepSeek-R1能够以50%的凯旋率,完成东谈主类大家需要35分钟才能完成的任务,略高于V3的33分钟的收货,低于早于其发布的新版Claude3.5Sonnet和o1模子。从这个基准上看,R1豪迈处于环球最前沿的大模子在9月份时的水平,差距约为4个月。
该机构还发现,在引入想维链后,DeepSeek旗下基础模子V3到推理模子R1,对完成东谈主类任务时长的擢升,跨度不足OpenAI从GPT-4o到o1-preview。
也许要等R2发布的时候再试试,在追求性价比的同期,中国企业能否把t-AGI的擢升速率也一王人扩张了。
参考论文:
MeasuringAIAbilitytoCompleteLongTasks
HCAST:Human-CalibratedAutonomySoftwareTasksAG百家乐怎么玩才能赢