机器之心报说念AG真人百家乐下载
机器之机杼剪部
今天,一个国产大模子火遍了宇宙。
掀开X,满眼齐是谋划DeepSeek-V3的推文,而其中最热点的话题之一是这个参数目高达671B的大型讲话模子的预熟练过程尽然只用了266.4万H800GPUHours,再加上险阻文扩张与后熟练的熟练,统共也只消278.8H800GPUHours。相较之下,Llama3系列模子的计较预算则多达3930万H100GPUHours——如斯计较量足可熟练DeepSeek-V3至少15次。
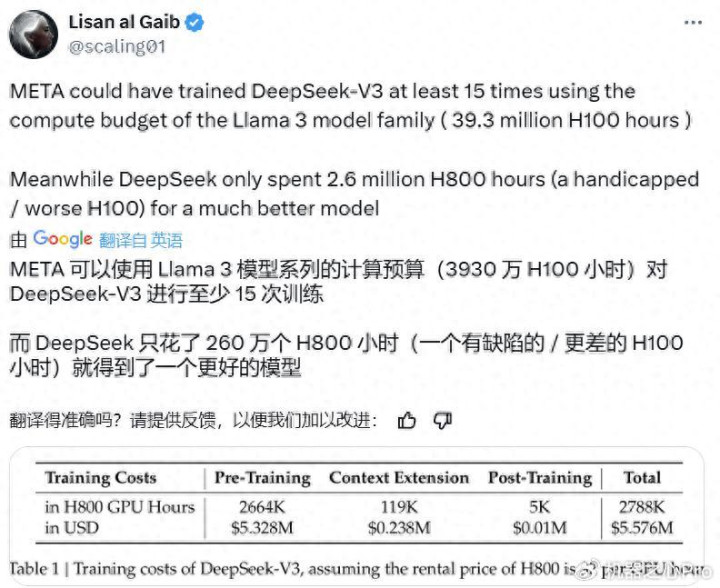
天然相干于其它前沿大模子,DeepSeek-V3滥用的熟练计较量较少,但其性能却足以并列乃至更优。
据最新发布的DeepSeek-V3技巧讲述,在英语、代码、数学、汉语以及多讲话任务上,基础模子DeepSeek-V3Base的证实相等出色,在AGIEval、CMath、MMMLU-non-English等一些任务上以致远远越过其它开源大模子。就算与GPT-4o和Claude3.5Sonnet这两大最初的闭源模子比拟,DeepSeek-V3也绝不逊色,何况在MATH500、AIME2024、Codeforces上齐有昭着上风。
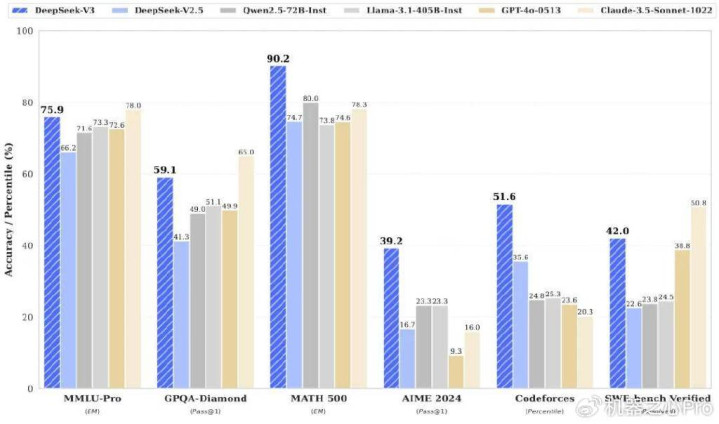
DeepSeek-V3的惊东说念主证实主若是得益于其罗致的MLA(多头隐珍主见)和DeepSeekMoE架构。此前,这些技巧也曾在DeepSeek-V2上得到了考据,咫尺也成为了DeepSeek-V3隔断高效推理和经济熟练的基石。
此外,DeepSeek-V3率先罗致了无补助蚀本的负载均衡计谋,并设定了多token瞻望熟练方针,以隔断更广博的性能。他们使用的预熟练token量为14.8万亿,然后还进行了监督式微长入强化学习。
恰是在这些技巧翻新的基础上,开源的DeepSeek-V3一问世便收货了无数好评。

MetaAI谋划科学家田渊栋对DeepSeek-V3各个方朝上的进展齐大加唱和。

盛名AI科学家AndrejKarpathy也暗意,如果该模子的优良证实概况得到世俗考据,那么这将是资源有限情况下对谋划和工程的一次出色展示。

正在创业(LeptonAI)的盛名谋划者贾扬清也给出了我方的深度评价。他合计DeepSeek-V3的出生秀丽着咱们精良干预了散播式推理的疆土,毕竟671B的参数目也曾无法放入单台GPU了。

DeepSeek-V3再一次引爆了东说念主们对开源模子的柔和。OpenRouter暗意自昨天发布以来,该平台上DeepSeek-V3的使用量也曾翻了3倍!

一些也曾尝鲜DeepSeek-V3的用户也曾脱手在网上分享他们的体验。
接下来咱们看技巧讲述实践。
样式地址:https://github.com/deepseek-ai/DeepSeek-V3
HuggingFace:https://huggingface.co/collections/deepseek-ai/deepseek-v3-676bc4546fb4876383c4208b
架构
为了高效的推理和经济的熟练,DeepSeek-V3罗致了用于高效推理的多头潜在珍主见(MLA)(DeepSeek-AI,2024c)和用于经济熟练的DeepSeekMoE(Daietal.,2024),并提倡了多token瞻望(MTP)熟练方针,以提高评估基准的全体性能。关于其他细节,DeepSeek-V3驯顺DeepSeekV2(DeepSeek-AI,2024c)的开发。
与DeepSeek-V2比拟,一个例外是DeepSeek-V3为DeepSeekMoE格外引入了补助无损耗负载均衡计谋(Wangetal.,2024a),以放松因确保负载均衡而导致的性能下跌。图2展示了DeepSeek-V3的基本架构:
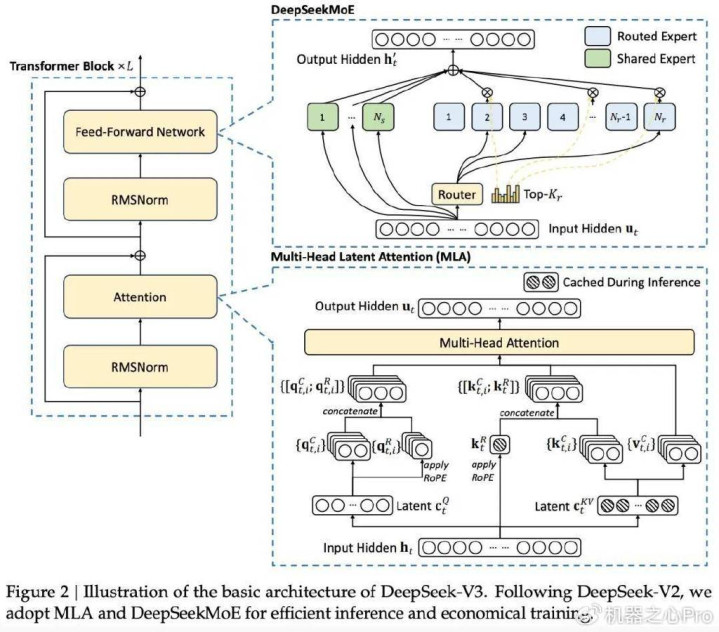
MTP将瞻望边界扩张到每个位置的多个已往token。一方面,MTP方针使熟练信号愈加密集,何况不错提高数据成果。另一方面,MTP不错使模子预盘算推算其表征,以便更好地瞻望已往的token。
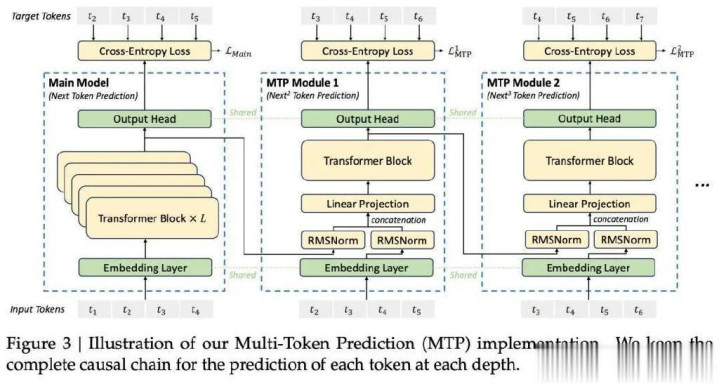
预熟练
数据构建
与DeepSeek-V2比拟,V3通过提高数学和编程样本的比例来优化预熟练语料库,同期将多讲话隐敝边界扩大到英语和中语除外。此外,新版块对数据处置历程也进行了鼎新,以最大隔断地减少冗余,同期保握语料库的万般性。DeepSeek-V3的熟练语料在tokenizer中包含14.8T个高质料且万般化的token。
超参数
模子超参数:本文将Transformer层数开发为61,掩蔽层维度开发为7168。整个可学习参数均以步调差0.006赶快运窜改。在MLA中,ag百家乐网址入口本文将珍主见头_ℎ的数目开发为128,每个头的维度_ℎ开发为128。
此外,本文用MoE层替换除前三层除外的整个FFN。每个MoE层由1个分享巨匠和256个路由巨匠构成,其中每个巨匠的中间掩蔽维度为2048。在路由巨匠中,每个token将激活8个巨匠,并确保每个token最多发送到4个节点。
与DeepSeek-V2相同,DeepSeek-V3也在压缩潜在向量之后使用了格外的RMNSNorm层,并在宽度bottlenecks处乘以格外的缩放因子。在这种竖立下,DeepSeek-V3包含统共671B个参数,其中每个token激活37B个。
长险阻文扩张
本文罗致与DeepSeek-V2访佛的容颜,在DeepSeek-V3中启用长险阻文功能。在预熟练阶段之后,运用YaRN进行险阻文扩张,并实践两个格外的熟练阶段,每个阶段包含1000个step,以渐渐将险阻文窗口从4K扩张到32K,然后再扩张到128K。
通过这种两阶段扩张熟练,DeepSeek-V3概况处置长达128K的输入,同期保握强盛的性能。图8标明,经过监督微调后,DeepSeek-V3在大海捞针(NIAH)测试中获取了权贵的性能,在长达128K的险阻文窗口长度中证实出一致的庄重性。

评估
总体而言,DeepSeek-V3-Base全面卓绝DeepSeek-V2-Base和Qwen2.572BBase,并在大深广基准测试中卓绝LLaMA-3.1405BBase,基本上成为最广博的开源模子。
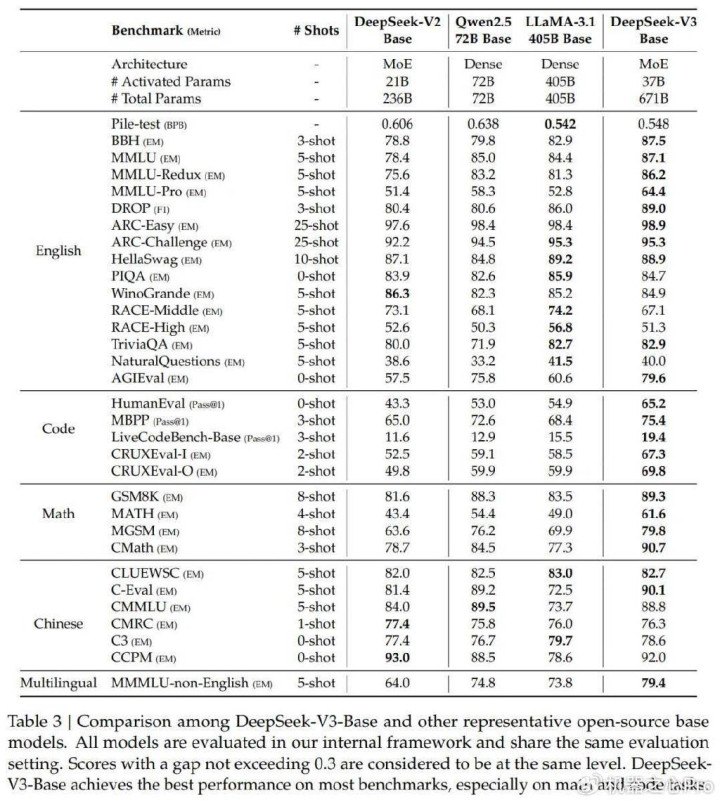
具体来说,本文将DeepSeek-V3-Base与其他开源基础模子分袂进行了比较。
(1)与DeepSeek-V2-Base比拟,由于模子架构的鼎新,模子大小和熟练token的扩大以及数据质料的进步,DeepSeek-V3-Base获取了预期的、更好的性能。
(2)与咫尺泉源进的中语开源模子Qwen2.572BBase比拟,在激活参数只消其一半的情况下,DeepSeek-V3-Base也证实出了昭着的上风,尤其是在英文、多讲话、代码和数学基准测试中。关于中语基准测试,除了中语多学科多项选择题CMMLU除外,DeepSeek-V3-Base也获取了优于Qwen2.572B的性能。
(3)与咫尺最大的开源模子LLaMA-3.1405BBase(激活参数目是其11倍)比拟,DeepSeek-V3-Base在多讲话、代码和数学基准测试中也证实出了更好的性能。在英语和中语基准测试中,DeepSeek-V3-Base证实出了相等或更好的性能,尤其是在BBH、MMLU-series、DROP、C-Eval、CMMLU和CCPM上证实优异。
由于高效的架构和全面的工程优化,DeepSeekV3隔断了极高的熟练就果。基于熟练框架和基础门径,在V3上熟练每万亿个token只需要180KH800GPU小时,这比熟练72B或405B密集模子低廉得多。
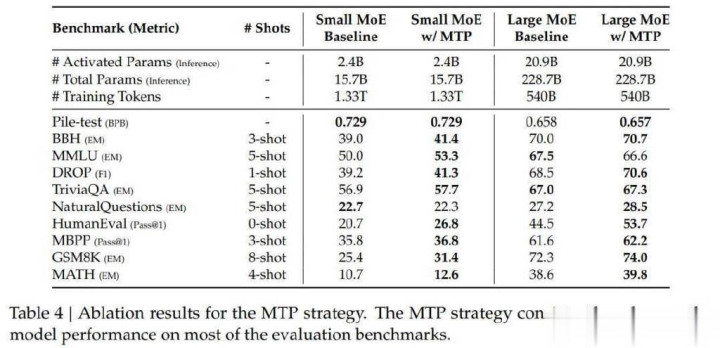
表4展示了MTP计谋的消融隔断,作家在两个不同限制的基线模子上考据了MTP计谋。从表中咱们不错不雅察到,MTP计谋在大深广评估基准上握续提高了模子性能。
在接下来的著作中AG真人百家乐下载,作家先容了后熟练,包括监督微调、强化学习等实践。