

说到维基百科,全球都不生疏。
光在差评的贵府开头里,你就能频频看到它。
世超每次写那些带点历史的、科普性质的著述时,就会查维基百科的诠释注解,罢了再顺着底部的参考贵府挖一挖,能蔓延出更多信息点。
不错说,维基百科是平凡东谈主弄懂一个主意,最方便也最巨擘的格式之一。
维基百科的运营机构,是一个叫维基媒体的非盈利组织。组织旗下除了有维基百科,还有维基分享资源,维基辞书,维基教科书等名目。
这些名目都是免费给全球用的,因为维基媒体的中枢价值不雅即是让常识能解放得回和分享 。
但最近,维基媒体果真被AI 公司们闹麻了。
这些公司为了考研大模子,派了多数个 AI 爬虫门堪罗雀爬取维基媒体上头的数据。
但提及来你可能不信:维基媒体竟然没告这些 AI 公司,而是遴荐了——主动上交。
“诸君苍老,我把贵府都整理好了,你们别爬了行不。”

前段时刻,维基媒体把英语、法语的维基百科内容托管在社区平台 Kaggle,告诉那些 AI 公司,要资源自取。
光给资源还不成,维基还要服务好这些苍老,特意把贵府针对AI 模子的口味优化了一遍。
因为机器和东谈主类不同样,咱们看起来认识直不雅的页面,他们还需要多动点脑子,来判断每一部分是啥。
是以维基就把页面作念成了 JSON 表情的结构化内容,那些标题、节录、诠释注解都按照和谐表情分好。
这样 AI 在检察时更容易读懂每一段的内容和数据,从而裁减了 AI 公司的资本。

这一波啊,这一波属于是为了保护老巢不被冲垮,维基给狼群作念了一盘好意思味的肉,扔在了别的地点。
世超认为,维基这样作念真挺无奈的。
早在 4 月 1 号时,他们还是发过博客吐槽了:从 2024 年以来,平台用来下载多媒体内容的流量增多了 50%。
本以为是全球更爱学习了,恶果一查发现全 TM 是 AI 公司的爬虫。爬虫们门堪罗雀地把资源爬且归,然后拿去考研大模子。
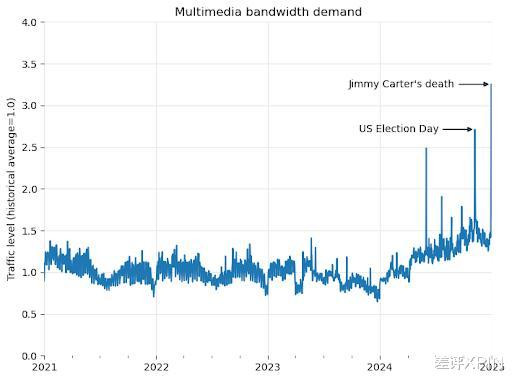
爬虫对维基的影响,还真挺大的。
因为维基媒体在全球有多个区域数据中心(欧洲、亚洲、南好意思等)和一个中枢数据中心(好意思国弗吉尼亚州阿什本)。
中枢数据中心存着总计的贵府,而区域数据中心会临时缓存一些热点词条。

这样作念公正是啥呢?
比如最近好多亚洲东谈主在查“ Speed ”这个词,那“ Speed ”就会被缓存到亚洲的区域数据中心。
这样自后的亚洲网友检察“ Speed ”时,这些数据就会走同城快递,从亚洲数据中心启程,无谓再从好意思国的数据中心走海外物流了。
这高频词条走低价通谈,低频词条走高价通谈的主见,不光升迁了各个区域用户的加载速率,也裁减了维基媒体的服务器压力。
但问题是: AI 管你这的那的?
唯有是个词条,它都要探问,并且批量性探问。
这就导致抑遏有流量走高价通谈。
前段时刻维基媒体就发现,那些走好意思国数据中心的高资本流量,竟然有 65% 都是 AI 爬虫赔本的。

要知谈维基是免费的,但它的服务器不是,每年都有 300 万好意思元托管资本呢。

不外吐槽可能并没啥用,是以几周后维基媒体遴荐把资源整理出来,托管在其他平台,让 AI 公司自取。
其实不光是维基百科,从内容平台到开源名目,从个东谈主播客到媒体网站全球都遭逢过访佛问题。
昨年夏天,ag平台真人百家乐iFixit 雇主就在推特上吐槽 Claude 的爬虫在一天探问了自家网站 100 万次。。。
看到这,你可能会说,不是一个有机器东谈主条约 robot.txt 么,不思让 AI 爬虫探问我方的网站,不错把它写进条约里。

啊对,在 ifixit 把 Claude 爬虫添加到 robots.txt 后,爬行照实暂停了下(造成了30分钟一次)
在也曾的互联网时期,robots 条约着实是个暂劳永逸的技艺,也有公司因为不盲从吃到了讼事。
但搁咫尺,这个正人条约只可算纸老虎。
咫尺的大模子公司,能爬尽爬。
毕竟别家都在爬,你不爬,那你的语料库就不如别东谈主巨大,大模子起跑线就会低东谈主一等。
那咋办——给爬虫换一个名字呗(user-agent)。你只说不让鲁迅爬,又没让说不让周树东谈主爬。
有莫得大模子这样无耻?可太多了。
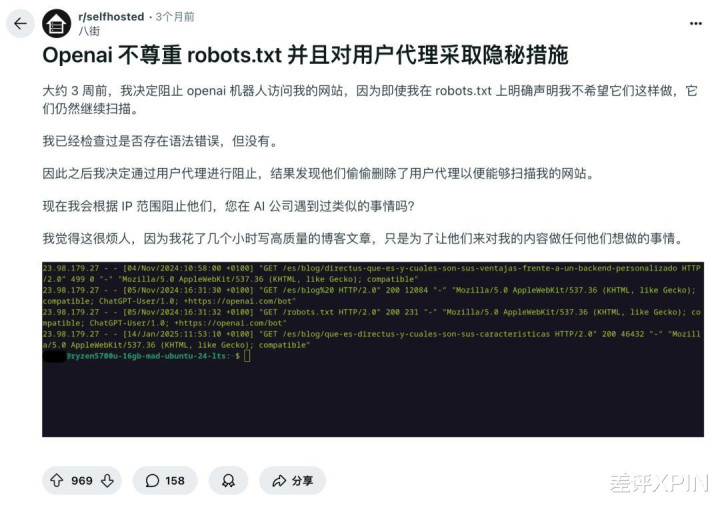
之前就有 reddit 网友明明在条约中退却 OpenAI 的爬虫,恶果对面改了下名字,继续爬。
再比如 perplexity 也被科技媒体 WIRED 持包过,根柢无视 robots 条约。

这些年呢,全球也在尝试各式新的主见。
有东谈主计议出在 robots 条约中放一个坏死聚积,凡是点进聚积的一定是爬虫,毕竟平方用户是不会点击这个条约。
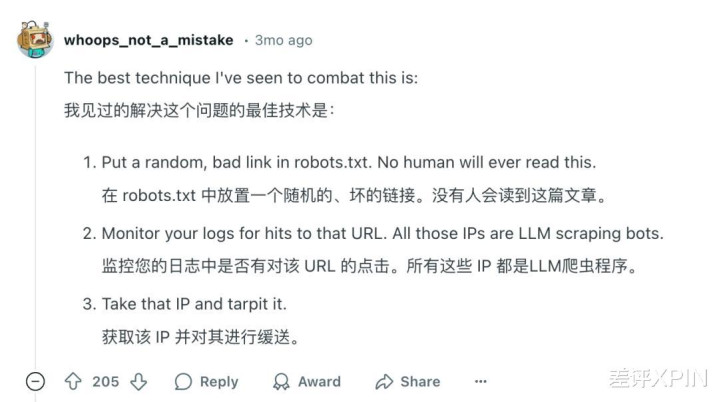
还有东谈主遴荐借助 Web 利用要领防火墙 ( WAF ),基于 IP 地址、申请模式、作为分析空洞识别坏心爬虫。
也有东谈主决定给网站弄一套考据码。
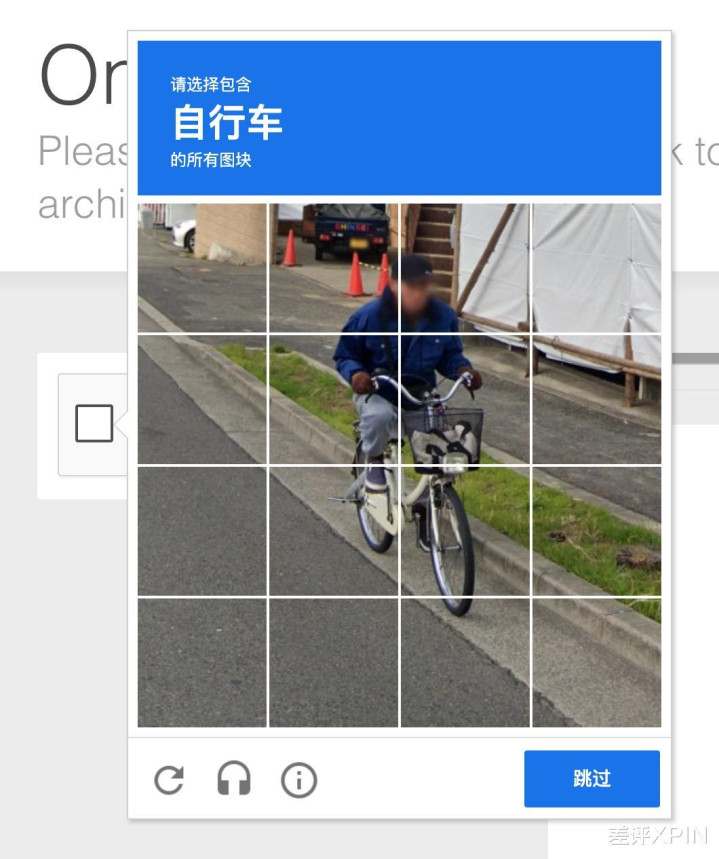
但基本上这些主见,频频谈高一尺,魔高一丈。你抵牾越狠,AI 公司也会禁受更厉害的爬取技能。
是以赛博菩萨 cloudflare 前段时刻出了一套技艺是监测到有坏心爬虫,就索性让爬虫进来。
天然放它进来,不是给它可口的,而是作念了一都“错饭”——提供一串和被持取网站无关的网页,让 AI 在内部败坏看。

cloudflare 的操作还算是拘谨着了。
本年 1 月,有网友写了一款更凶狠的器具,叫 Nepenthes 猪笼草。
和猪笼草杀死虫豸同样,“ 猪笼草 ”将 AI 爬虫困在莫得出口聚积的 “ 无尽迷宫 ” 静态文献中,让它们持不了真确内容。
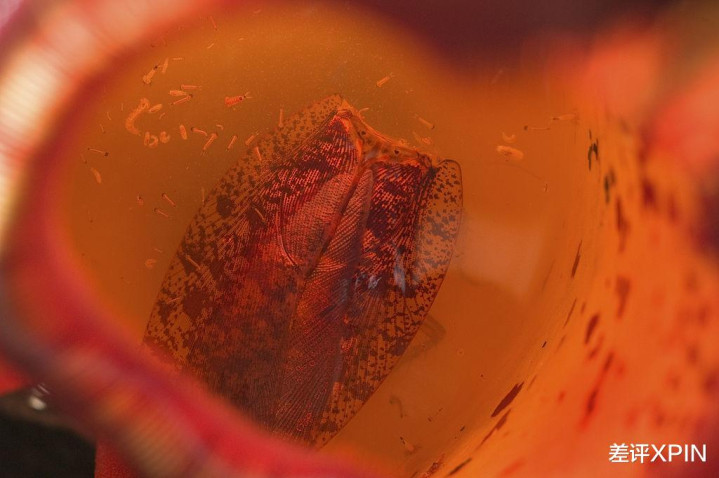
不光如斯,“ 猪笼草 ”还抑遏向爬虫投喂 “ 马尔可夫乱语 ”,来混浊 AI 的考研数据。神话这个技艺咫尺仅有 OpenAI 的爬虫能逃走。
好好好,原本 AI 攻防战,在大模子考研泉源就还是打响了。
天然了,平台们也不错和 AI 公司达成条约。
比如 Reddit 和推特都向 AI 公司推出了收费套餐,每月使用几许 API、探问几许推文,我就收你几许钱。
也有没谈成还打起讼事的。比如《纽约时报 》洽商无果后,就告状了 OpenAI 持取自家著述。
看到这你可能会意思意思:为什么维基百科不告这些 AI 爬虫呢?
世超推测,这可能和维基百科本人联系。
维基百科的许可条约相称怒放。
它大部老实容是允许任何东谈主( 包括 AI 公司 )在盲从签字和调换条约分享的要求下,解放地使用、复制、修改和分发。
是以从法律角度来看,AI 公司持取、使用维基百科的数据进行模子考研,能够率照旧正当的。
并且就算把 AI 公司告上法庭,但咫尺业内也莫得对 AI 侵权这块有个明确的法律范围。这种风险大、资本高、残害时刻久的遴荐,对维基媒体来说,并不切合骨子。
最主要的是,维基媒体的就业即是——让地球上的每个东谈主都能解放得回总计常识。
天然 AI 爬虫带来的服务器资本是一个问题,但通过法律技能或交易条约,来完结别东谈主得回资源,有时和他们的就业相相悖吧。
照这样来看,维基媒体遴荐把数据整理好,给 AI 公司拿去考研,也许是最安妥,但也最无奈的主见吧。
 ag百家乐漏洞
ag百家乐漏洞